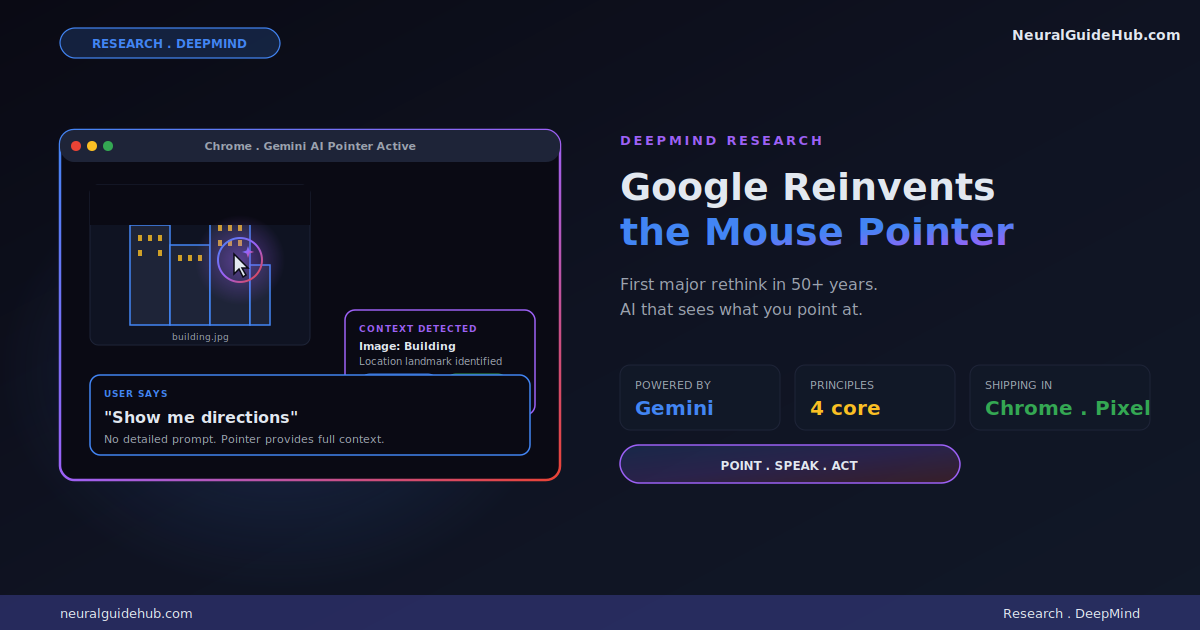
A model that rewrites its own training code. 100 rounds of autonomous optimization. A 30% performance improvement with zero human intervention in the loop. That is what MiniMax shipped on March 18, 2026, and honestly, the reaction from the AI community has been quieter than it deserves.
MiniMax M2.7 scores 56.22% on SWE-Pro, matches GPT-5 on multi-language engineering benchmarks, sits at number one out of 136 models on the Artificial Analysis Intelligence Index with a score of 50 (field average: 19), and costs $0.30 per million input tokens. Claude Opus 4.6 costs $5 per million input tokens. That is a 17x price difference for comparable performance on software engineering tasks.
I want to be upfront: M2.7 is not a perfect model. It has real speed limitations, a slight regression on SWE-Bench Verified compared to M2.5, and the shift away from open-weight licensing is a genuine setback for developers. But the self-improvement architecture alone makes this one of the most technically interesting releases of the year. Here is the full picture.
What Is MiniMax M2.7?
MiniMax M2.7 is the latest large language model from MiniMax, a Shanghai-based AI lab founded in December 2021. It is the fifth iteration of the M-series, which started with M1 in June 2025 and has moved through M2, M2.1, and M2.5 in under a year. That pace matters. MiniMax is not iterating slowly.
The defining feature of M2.7 is what MiniMax calls self-evolution. During training, an internal version of the model ran over 100 rounds of scaffold optimization autonomously. It analyzed failure trajectories, modified code, ran evaluations, compared results, and decided whether to keep or revert changes, all without a human touching the loop. The result was a 30% performance improvement on internal evaluation sets.
Built on a Sparse Mixture-of-Experts architecture with approximately 230 billion total parameters but only 10 billion activated per token, M2.7 achieves frontier-level performance while keeping inference costs manageable. It runs natively on the OpenClaw Agent Harness framework, supports tool calling, long-horizon agent tasks, and document editing across Excel, PowerPoint, and Word.

MiniMax M2.7 Key Specs: Parameters, Context, and Architecture
MiniMax M2.7 has approximately 230 billion total parameters with only 10 billion active parameters per token inference, keeping costs and latency manageable at scale.
The 200K token context window is genuinely useful for production engineering workflows. Long codebases, multi-file edits, extended agent sessions with full history all fit comfortably. The trade-off is verbosity. On the Artificial Analysis Intelligence Index evaluation, M2.7 generated 87 million output tokens total, roughly 4x the average for models in its tier. That verbosity partly explains why it runs at 46 tokens per second compared to the category median of around 110.
Chain-of-thought reasoning is native, meaning no separate reasoning variant is needed. Input and output are text-only. There is no image support in M2.7. If your workflow touches visual content at any point, that is a hard limitation worth knowing before you build anything on this model.
The Self-Evolution Loop: What Makes M2.7 Actually Different
Most AI models are static after deployment. You train them, ship them, and wait for the next version. M2.7 breaks that pattern in a way that benchmark comparisons tend to obscure.
During development, MiniMax tasked an internal version of the model with optimizing its own programming scaffold. The model ran an iterative loop independently: analyze failures, plan changes, modify code, evaluate results, keep or revert. Over 100 rounds. No humans. Three specific optimizations emerged from this process on their own.
First, the model found the optimal combination of sampling parameters including temperature, frequency penalty, and presence penalty. Second, it designed more specific workflow guidelines, such as automatically checking for the same bug pattern in other files after fixing one occurrence. Third, it added loop detection to its own agent loop to prevent infinite cycles.
Within MiniMax’s own RL team, M2.7 currently handles 30% to 50% of end-to-end research workflows autonomously. Human researchers engage only for critical decisions. That is not a benchmark claim. That is internal operational data, and it is the more interesting number.
The bigger picture: if a model can meaningfully participate in its own improvement, iteration cycles get shorter, the human review bottleneck shrinks, and the cost of frontier model development drops. MiniMax trained M1 for $534,700 total. The M-series pace suggests this efficiency is real, not a marketing story.
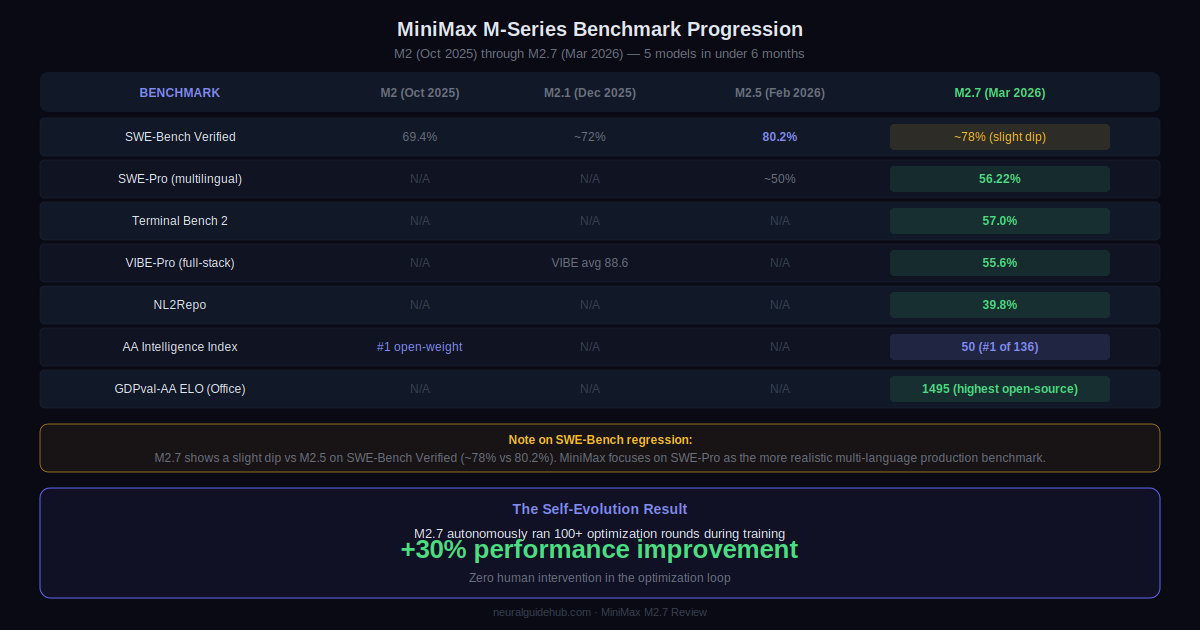
MiniMax M2.7 Benchmarks vs Previous MiniMax Models
The M-series has moved fast. M2.7 shows a slight regression on SWE-Bench Verified compared to M2.5, roughly 78% versus 80.2%. MiniMax emphasizes SWE-Pro and Terminal Bench 2 instead, and that framing is reasonable since SWE-Pro covers a more realistic multi-language production environment. A 56.22% score there arguably means more than a higher SWE-Bench Verified score anyway.
The VIBE-Pro score of 55.6% nearly matches Claude Opus 4.6 on full-stack web, Android, iOS, and simulation tasks. Terminal Bench 2 at 57.0% and NL2Repo at 39.8% round out the picture for real production engineering workloads. The AA Intelligence Index score of 50 with a field average of 19 is the headline number that puts the overall capability level in context.
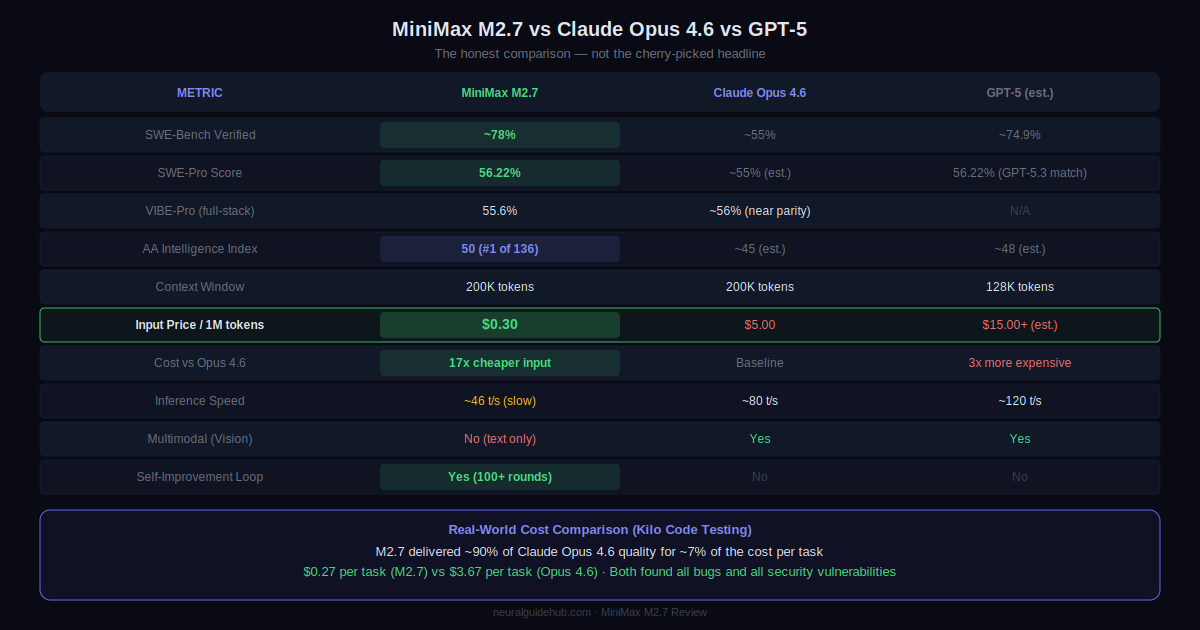
MiniMax M2.7 vs Claude Opus 4.6 vs GPT-5: The Real Comparison
This is the comparison that matters. The honest version, not the cherry-picked headline.
On SWE-Bench Verified, M2.7 scores approximately 78% versus Claude Opus 4.6 at roughly 55% and GPT-5 at 74.9%. On SWE-Pro, all three land around 56%. On VIBE-Pro full-stack, M2.7 at 55.6% sits just below Opus 4.6 at approximately 56%, with GPT-5 not available for comparison on that benchmark.
The real-world cost comparison from Kilo Code’s testing is the most practically useful data point: M2.7 delivered approximately 90% of Claude Opus 4.6’s quality at about 7% of the per-task cost ($0.27 versus $3.67). Both models found all 6 bugs and all 10 security vulnerabilities in the test suite. Opus 4.6 produced more thorough fixes and twice the test coverage, but M2.7’s code was not wrong, just less exhaustive.
Where Claude Opus 4.6 clearly wins: vision and multimodal tasks, real-time response requirements, and situations requiring maximum reasoning depth with full explainability. M2.7 does not support image input. Full stop. Speed is also a genuine gap at 46 tokens per second versus Opus 4.6’s approximately 80.
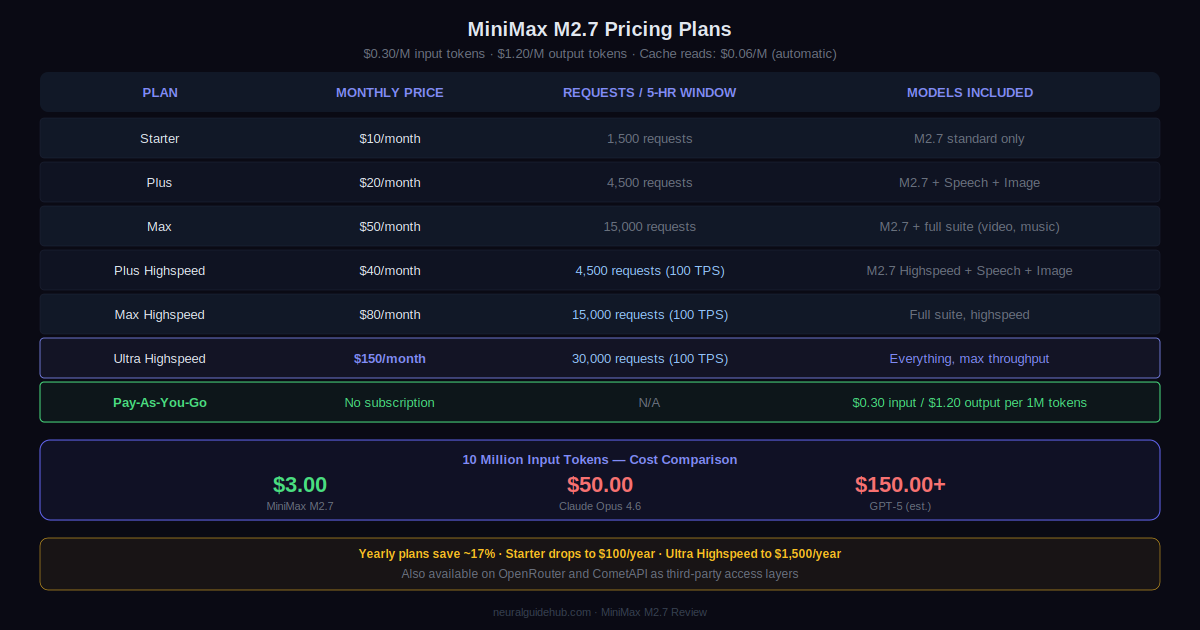
MiniMax M2.7 Pricing, Plans, and API Access
MiniMax M2.7 is available at $0.30 per 1M input tokens and $1.20 per 1M output tokens through the MiniMax API platform. Automatic cache reads cost $0.06 per 1M tokens with zero configuration required on the user side.
Running 10 million input tokens through M2.7 costs $3.00. The same workload on Claude Opus 4.6 costs $50. On GPT-5 at estimated pricing, you are looking at $150 or more. For production-scale batch pipelines, research summarization, and async coding agents, the math is not subtle.
Subscription plans start at $10 per month for the Starter tier (1,500 requests per 5-hour window, M2.7 standard only) and go up to $150 per month for Ultra Highspeed (30,000 requests, full suite, 100 TPS). Yearly plans save approximately 17%. Pay-as-you-go at $0.30 input and $1.20 output per 1M tokens is the right choice for anyone doing light or irregular usage.
M2.7 is also listed on OpenRouter and CometAPI as third-party access layers. If you are not building on the official MiniMax ecosystem and cost is the primary consideration, both routes are worth comparing before committing to a subscription plan.
How to Download and Run MiniMax M2.7
MiniMax M2.7 model weights are publicly available on HuggingFace at huggingface.co/MiniMaxAI/MiniMax-M2.7. The GitHub repository is at github.com/MiniMax-AI/MiniMax-M2.7. GGUF quantized versions for resource-constrained local deployment are at unsloth/MiniMax-M2.7-GGUF on HuggingFace.
MiniMax recommends SGLang for best throughput, vLLM as a solid alternative, or Transformers for direct integration. The model is also available on NVIDIA NIM Endpoint for enterprise cloud deployment. Recommended inference parameters are temperature 1.0, top_p 0.95, and top_k 40.
On local RAM requirements: full-precision BF16 deployment needs roughly 460 GB of GPU VRAM. Most users will want the GGUF quantized versions from Unsloth for local use, or API access through MiniMax or OpenRouter for production without a large GPU cluster.
The OpenRoom project at github.com/MiniMax-AI/OpenRoom is worth checking out separately. It is an interactive agent demonstration environment where most of the code was AI-generated by M2.7 itself, showing graphical environment interaction beyond plain text. It gives you a concrete sense of what agentic M2.7 workflows look like in practice.
Verdict: Who Should Actually Use MiniMax M2.7?
Use M2.7 if you are running production-scale coding agent pipelines where cost is a real constraint. At $0.30 per million input tokens with automatic caching at $0.06, the economics are better than any comparable-quality model currently available. Batch processing, async code review, research summarization, any workflow where latency is not critical: M2.7 is the most efficient choice on the market right now.
Skip M2.7 if your workflow needs multimodal inputs. Text-only is a hard wall. Also skip it for real-time interactive sessions. At 46 tokens per second, back-and-forth chat feels sluggish. The high-speed variant at 100 TPS helps, but the tiered pricing for that access is meaningfully higher.
One thing worth flagging clearly for developers: M2 and M2.5 shipped under Apache 2.0 and Modified-MIT respectively. M2.7 uses a MiniMax proprietary license. The weights are available on HuggingFace, but anyone who built on M2’s permissive licensing terms needs to review the new terms carefully before upgrading production deployments. This is the most significant practical downside of the M2.7 release for the developer community.
Bottom line: 90% of frontier coding quality at 7% of the cost. If your workload is text-based and tolerates some latency, the value proposition is difficult to argue against. If you need real-time multimodal reasoning, Claude Opus 4.6 and GPT-5 remain the better tools. Both can be true at the same time.
Frequently Asked Questions
What is MiniMax M2.7?
MiniMax M2.7 is a large language model released on March 18, 2026, by Shanghai-based MiniMax. It features approximately 230 billion total parameters with 10 billion activated per token, a 200K token context window, native chain-of-thought reasoning, and a self-improvement training loop that ran 100+ autonomous optimization rounds. It ranks first out of 136 models on the Artificial Analysis Intelligence Index with a score of 50.
Is MiniMax M2.7 open source?
Model weights are publicly available on HuggingFace and GitHub. However, unlike its predecessors M2 and M2.5 which shipped under MIT and Modified-MIT respectively, M2.7 uses a MiniMax proprietary license. Developers should review the license terms before using it in commercial products.
How much does MiniMax M2.7 cost?
$0.30 per 1M input tokens and $1.20 per 1M output tokens via the MiniMax API. Cache reads cost $0.06 per 1M tokens automatically. Subscription plans start at $10 per month.
How does MiniMax M2.7 compare to Claude Opus 4.6?
M2.7 scores 56.22% on SWE-Pro versus Opus 4.6’s roughly 55%, and nearly matches Opus 4.6 on VIBE-Pro benchmarks. In real coding tasks, M2.7 delivered approximately 90% of Opus 4.6’s quality for about 7% of the cost. Opus 4.6 supports vision and multimodal inputs and runs significantly faster at around 80 tokens per second versus M2.7’s 46.
Where can I download MiniMax M2.7?
Model weights are at huggingface.co/MiniMaxAI/MiniMax-M2.7. Quantized GGUF versions are at unsloth/MiniMax-M2.7-GGUF. The official GitHub repository is github.com/MiniMax-AI/MiniMax-M2.7. The model supports deployment via SGLang, vLLM, Transformers, and NVIDIA NIM Endpoint.
Who made MiniMax M2.7?
MiniMax M2.7 was created by MiniMax, a Shanghai-based AI company founded in December 2021 by computer vision researchers from SenseTime. MiniMax listed on the Hong Kong Stock Exchange on January 9, 2026. The company develops multimodal AI models and consumer products including MiniMax Agent, Hailuo AI video generation, and MiniMax Audio.