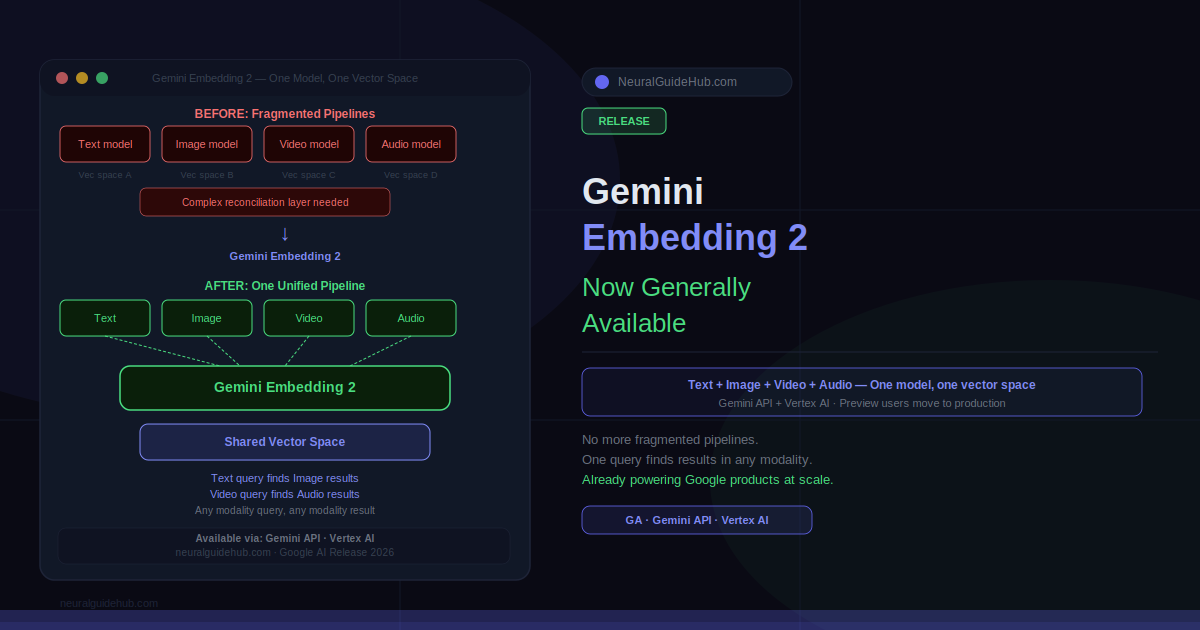
Building a search system that understands both a product image and its text description used to mean two separate embedding models, two pipelines, and a retrieval layer trying to reconcile outputs that were never designed to talk to each other. That fragmentation was the cost of working with multimodal data before a single model could handle all of it in the same vector space. Gemini Embedding 2 is now generally available, and the core thing it changes is exactly that: one model, one embedding space, across text, image, video, and audio.
During the preview phase, developers built e-commerce discovery engines that could search across product images and descriptions simultaneously, and video analysis tools that didn’t require separate transcription and visual processing pipelines before retrieval could happen. Those prototypes are now production-ready. The GA release on the Gemini API and Vertex AI brings the stability, SLAs, and optimizations that production deployments require.
What Gemini Embedding 2 Actually Does
Embeddings convert data into numerical vectors that capture semantic meaning. When you search for “running shoes for flat feet” and get results that include images of relevant shoes without that exact phrase in the product description, embeddings are doing that work. The quality of the embedding model determines how accurately semantic relationships survive the conversion to vectors.
What makes Gemini Embedding 2 different is native multimodality. Previous approaches required separate embedding models for different data types: one for text, one for images, potentially another for video. Then a retrieval system had to reconcile embeddings from different vector spaces to surface relevant results across modalities. That architecture worked, but it introduced complexity, latency, and alignment problems that grew with the number of modalities involved.
Gemini Embedding 2 processes text, image, video, and audio into a shared vector space using a single model. A query in text can retrieve results that are images. A video clip can be used as a query to find related audio content. The semantic relationships that make retrieval useful apply across modalities rather than within each one separately.
What Changed from Preview to GA
The preview period produced real-world signal about where the model performed well and where it needed refinement. E-commerce discovery and video analysis were the two most prominent preview use cases, which makes sense: both involve large-scale retrieval across mixed modality data, and both require the kind of semantic accuracy that shows up in actual user behavior rather than benchmark scores.
The GA release adds the production-grade stability that enterprise deployments require. That means consistent API behavior, service-level agreements, and the performance optimizations that make sense to invest in only after a model’s behavior is locked. Preview phases exist specifically to surface the real-world requirements that synthetic benchmarks miss, and the optimizations in the GA version reflect what actually mattered to the teams building with it during preview.
Access: Gemini API and Vertex AI
Gemini Embedding 2 is available through two paths. The Gemini API is the direct route for developers building with Google’s AI stack. Vertex AI is the enterprise path, with the managed infrastructure, access controls, and compliance tooling that larger organizations require for production deployments.
Both paths give access to the same underlying model. The choice between them is an infrastructure and operational question rather than a capability question. Teams already on Vertex AI for other Google AI services can add Gemini Embedding 2 without introducing a separate API dependency.
The Practical Impact for Search and Retrieval
The most immediate practical impact is on search systems that need to work across data types. An e-commerce platform with product images, descriptions, and customer reviews currently handles those three differently at the retrieval layer. With Gemini Embedding 2, all three can live in the same vector space and be retrieved with a single query regardless of the query’s modality.
Video analysis is the other obvious application. Video contains visual frames, audio, and often transcribed speech. Treating those separately means running multiple models and then reconciling their outputs, which adds latency and introduces alignment problems. A single multimodal embedding model processes the video as a whole, which simplifies the pipeline and produces retrieval results that reflect the actual semantic content of the video rather than its components analyzed in isolation.
Google describes Gemini Embedding 2 as a core technology powering several Google products, which means the model has been tested at significant scale before the developer GA. That production history is worth noting for teams evaluating reliability: this is not a research model being released externally for the first time. It’s a model with demonstrated production use at Google’s scale, now available for general use through the API and Vertex AI.