Last week a senior engineer at a large tech company told me he’d been using an early version of GPT-5.5 and losing access to it felt like, in his words, having a limb amputated. That’s a dramatic thing to say about a language model. But if you’ve spent real time with previous coding AI and know exactly where they stop being useful — the moment a task gets complex enough that they lose the thread — you understand what he meant.
GPT-5.5 is OpenAI’s new flagship model, built specifically for agentic work. Not just writing code. Planning, using tools, checking its own output, navigating through ambiguous failures, and continuing until the task is actually done. The other technical claim worth noting: it matches GPT-5.4’s per-token latency in production. Bigger, smarter models are almost always slower. Getting there without a speed penalty required rethinking how inference works, and they did it partly by having GPT-5.5 and Codex optimize the infrastructure stack themselves.
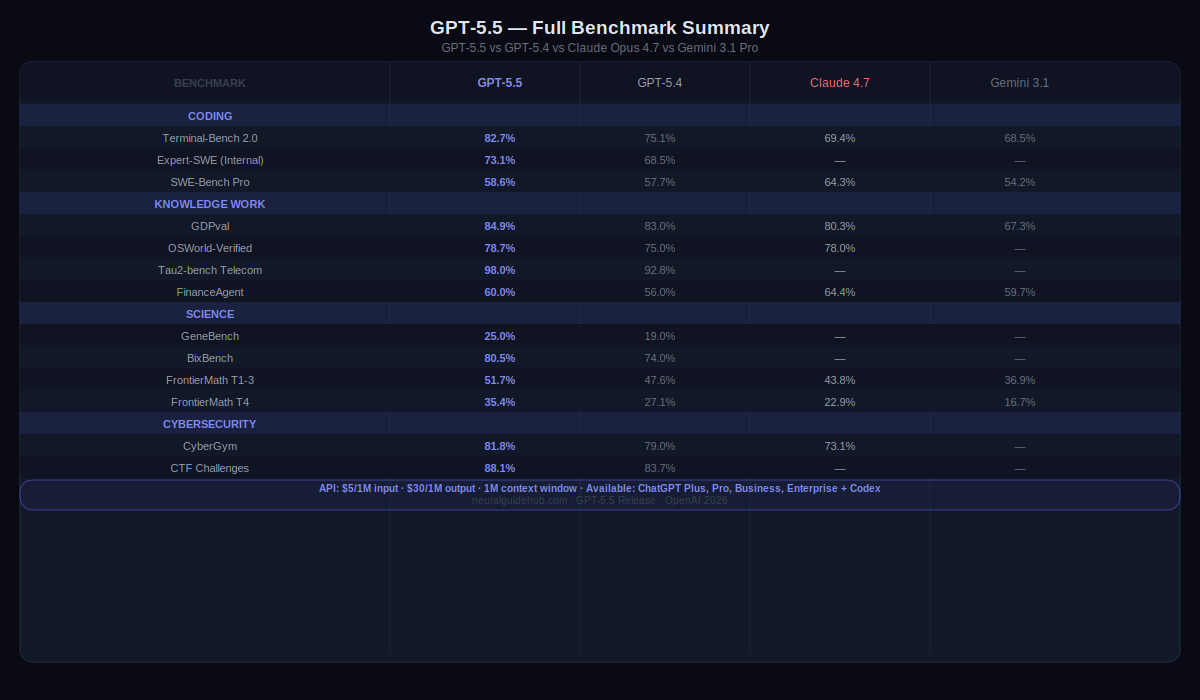
What GPT-5.5 Actually Does Better at Coding
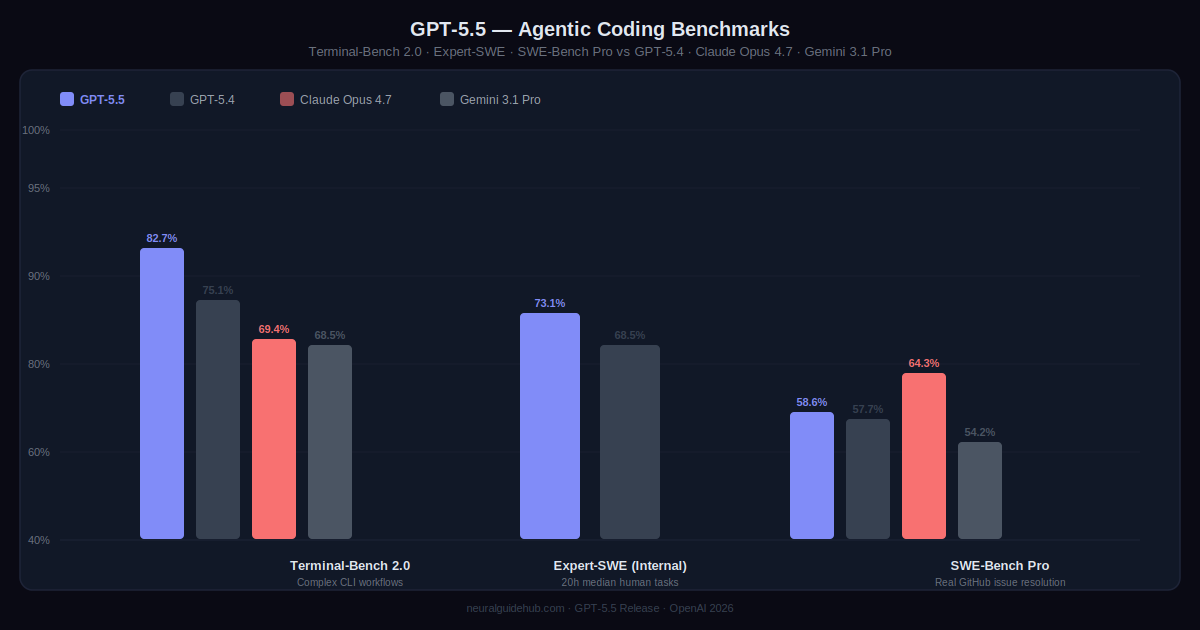
Terminal-Bench 2.0 is the benchmark I pay attention to for agentic coding. It tests complex command-line workflows — the kind that require planning ahead, adjusting based on partial results, coordinating multiple tools, and not giving up when something breaks halfway through. GPT-5.5 scores 82.7% on it. GPT-5.4 scored 75.1%. Claude Opus 4.7 scored 69.4%.
That gap isn’t from one lucky run. It reflects something specific: the model holds context across a longer chain of steps without losing what it was trying to do. On Expert-SWE, OpenAI’s internal benchmark for coding tasks with a median human completion time of 20 hours, GPT-5.5 outperforms GPT-5.4 while using fewer tokens to get there. Less compute, better result.
Dan Shipper, CEO of Every, put it plainly: “the first coding model I’ve used that has serious conceptual clarity.” His test was blunt. Take a broken production system that his best engineer had spent days debugging before deciding to rewrite part of it. Ask GPT-5.5 to look at the broken state cold and produce the same kind of rewrite. GPT-5.4 couldn’t do it. GPT-5.5 did.
Pietro Schirano, CEO of MagicPath, used it to merge a branch with hundreds of frontend and refactor changes into a main branch that had also diverged significantly. Resolved in one shot. About 20 minutes. Engineers testing the model said it consistently caught issues before being asked about them and predicted what testing and review steps would be needed. That’s a different behavior from a model that waits for you to notice problems.
Knowledge Work: GPT-5.5 on Computers, Not Just Code
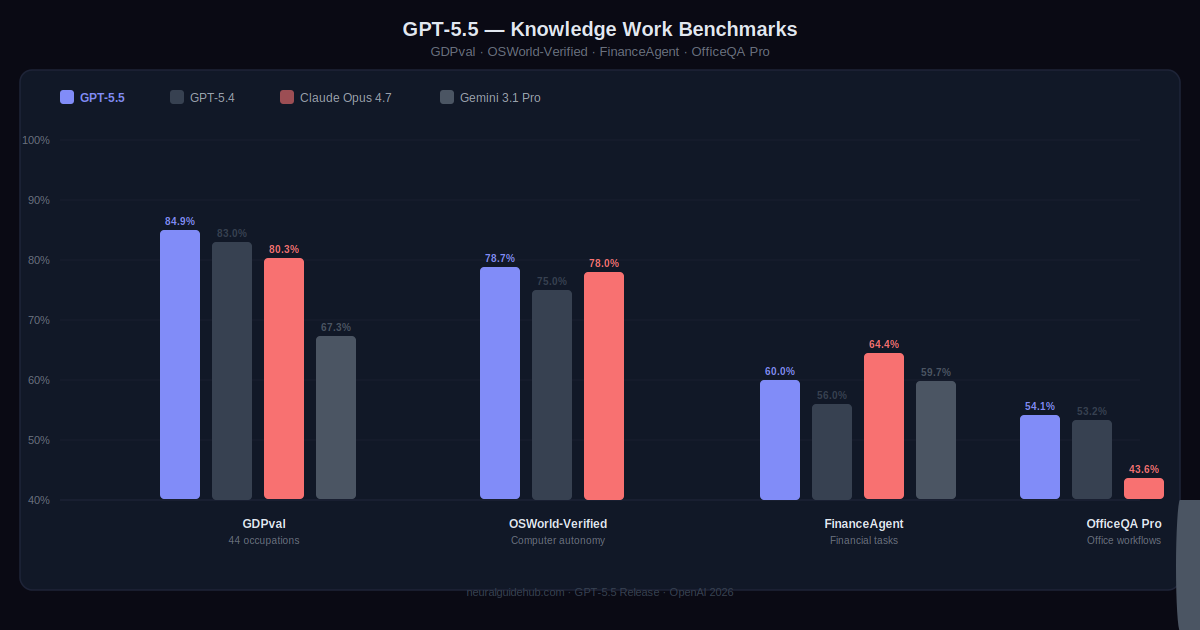
OpenAI’s GDPval benchmark covers 44 different occupations and tests whether an agent can produce professional-quality work across that range. GPT-5.5 scores 84.9%. That’s across accountants, analysts, marketing roles, legal work, and more. On OSWorld-Verified, which tests whether the model can actually operate a real computer by seeing a screen, clicking, typing, and navigating interfaces, it scores 78.7%.
The internal OpenAI examples are worth reading. Over 85% of the company now uses Codex every week. The finance team reviewed 24,771 K-1 tax forms totaling 71,637 pages using a GPT-5.5 workflow and finished two weeks ahead of the prior year. A comms team built a Slack agent that auto-handles low-risk speaking requests. One go-to-market employee automated a weekly report that was eating five to ten hours per week. These aren’t edge cases. They’re repeatable workflows that used to require a human every time.
Scientific Research: Something Genuinely New
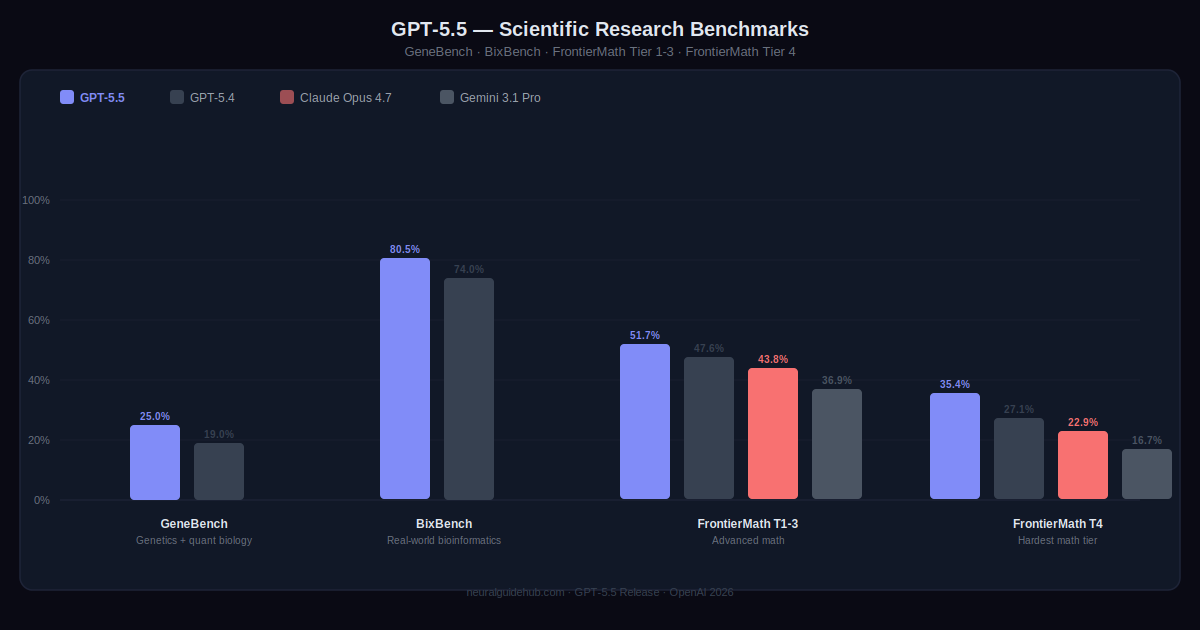
GeneBench measures multi-stage scientific data analysis in genetics and quantitative biology. Problems where the model has to work through ambiguous or errorful data with minimal guidance, handle hidden confounders and QC failures, and apply modern statistical methods correctly. GPT-5.5 scores 25.0%. GPT-5.4 scored 19.0%. On BixBench, real-world bioinformatics tasks, GPT-5.5 reaches 80.5% versus GPT-5.4’s 74.0%.
The result that doesn’t fit into a benchmark is worth mentioning separately. An internal version of GPT-5.5 with a custom harness found a new proof about off-diagonal Ramsey numbers — a longstanding open question in combinatorics — later verified in Lean. This is not GPT-5.5 explaining what a Ramsey number is. It’s contributing an actual mathematical argument that didn’t exist before. That’s a different kind of claim.
Derya Unutmaz, immunology professor at the Jackson Laboratory for Genomic Medicine, used GPT-5.5 Pro to analyze 62 samples across nearly 28,000 genes, getting back a detailed research report with surfaced insights and open questions. He said the analysis would have taken his team months. Bartosz Naskrecki, a math professor in Poland, used Codex to build an algebraic geometry app from a single prompt in 11 minutes.
Cybersecurity Capabilities and GPT-5.5 Safeguards
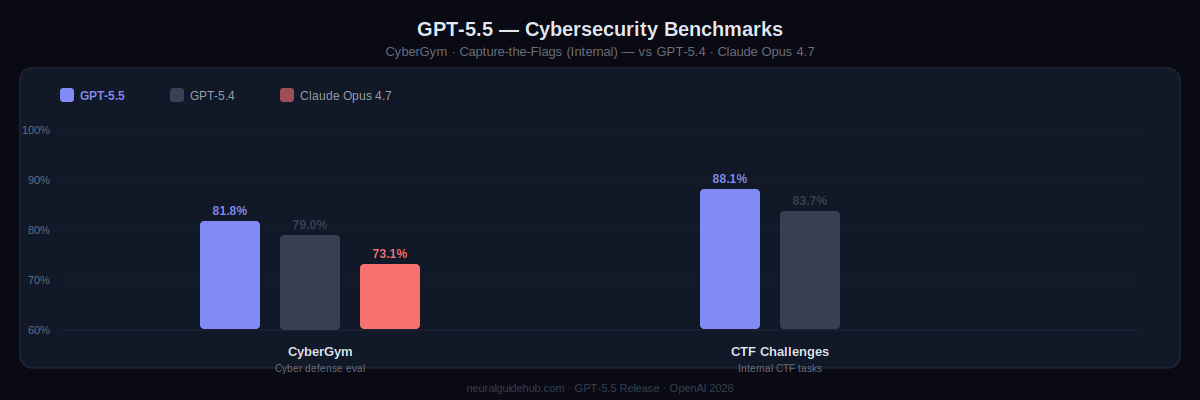
CyberGym: GPT-5.5 scores 81.8%. GPT-5.4 was 79.0%. Claude Opus 4.7 scored 73.1%. On internal Capture-the-Flag challenge tasks, GPT-5.5 reaches 88.1% versus GPT-5.4’s 83.7%. OpenAI rates the model’s cybersecurity capabilities as High under the Preparedness Framework. It didn’t hit Critical level, but it’s a step up from GPT-5.4 in a category where steps up matter.
New stricter classifiers are deployed with this release for high-risk cyber requests. Some legitimate users will find them frustrating initially. That’s acknowledged. The Trusted Access for Cyber program gives verified security professionals and defenders expanded access with fewer restrictions. Individual verification happens at chatgpt.com/cyber. Organizations defending critical infrastructure can apply for cyber-permissive model access separately.
Pricing and Availability
Rolling out now to Plus, Pro, Business, and Enterprise in ChatGPT and Codex. GPT-5.5 Pro is going to Pro, Business, and Enterprise in ChatGPT. API access is coming soon.
When the API goes live: $5 per million input tokens, $30 per million output tokens, 1M context window. Batch and Flex at half the standard rate. Priority at 2.5x. GPT-5.5 Pro: $30 input, $180 output per million tokens.
It costs more than GPT-5.4. That’s straightforward. But it completes the same Codex tasks with significantly fewer tokens, and on the Artificial Analysis Coding Index it delivers its intelligence level at roughly half the per-token cost of competing frontier coding models. For agentic workflows where a task runs for hundreds of steps, token efficiency is the number that matters, not the headline rate.