Preview releases are tricky. Ship too early and the benchmarks don’t hold up in real use. Ship too late and the moment has passed. Alibaba’s Qwen team is walking that line openly with Qwen3.6-Max-Preview, their next proprietary model after Qwen3.6-Plus. They are calling it a preview explicitly, noting the model is still under active development. That honesty is refreshing. And the numbers are interesting enough that the preview is worth understanding now.
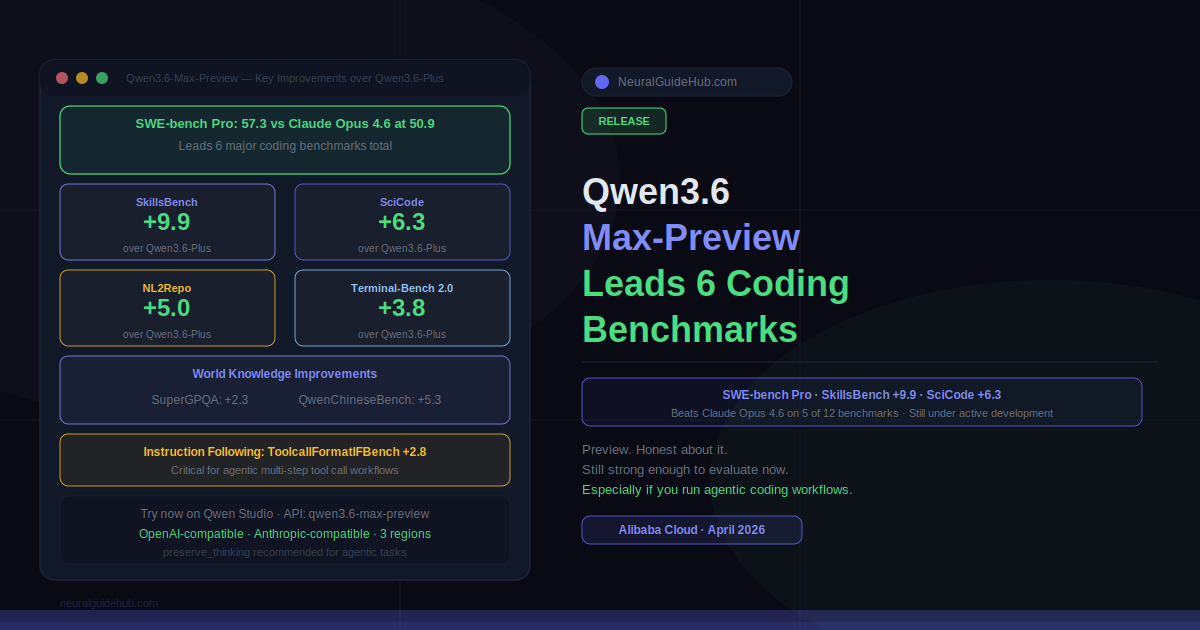
The short version: Qwen3.6-Max-Preview leads on six major coding benchmarks, improves meaningfully on world knowledge, and tightens up instruction following. It beats Claude Opus 4.6 on SWE-bench Pro. That last point alone is enough to get the attention of anyone running agentic coding workflows.
What Changed from Qwen3.6-Plus
The improvements are concrete and measurable. On agentic coding, SkillsBench is up 9.9 points, SciCode up 6.3, NL2Repo up 5.0, and Terminal-Bench 2.0 up 3.8 over Qwen3.6-Plus. Those are not rounding-error improvements. SkillsBench at plus 9.9 is a significant jump for a preview release on an already-capable model.
World knowledge also improved. SuperGPQA is up 2.3 and QwenChineseBench up 5.3, which matters for teams deploying in multilingual or knowledge-intensive contexts. Instruction following, measured through ToolcallFormatIFBench, is up 2.8 points. For agentic workflows where the model needs to follow complex, structured tool call formats reliably, that number has real operational implications.
Qwen3.6-Max-Preview Benchmark Results
The model leads on six benchmarks: SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode. Some of the specific numbers worth noting.
On SWE-bench Pro, Qwen3.6-Max-Preview scores 57.3, ahead of Claude Opus 4.6 at 50.9, Qwen3.6-Plus at 56.6, and GLM 5.1 at 58.4. On SciCode, it reaches 47.0 versus Claude at 42.0 and Qwen3.6-Plus at 40.7. On SkillsBench, the score is 55.6 against Qwen3.6-Plus at 45.7 and Claude at 45.3. On SuperGPQA for graduate-level knowledge, it hits 73.9 against 71.6 for Qwen3.6-Plus and 70.4 for Claude.
QwenWebBench is the outlier where the model does not lead. GLM 5.1 scores 1558 versus Qwen3.6-Max-Preview’s 1532 on that Elo rating benchmark. Worth noting. The model is not uniformly first across every dimension, which makes the evaluation more credible, not less.

How to Access Qwen3.6-Max-Preview
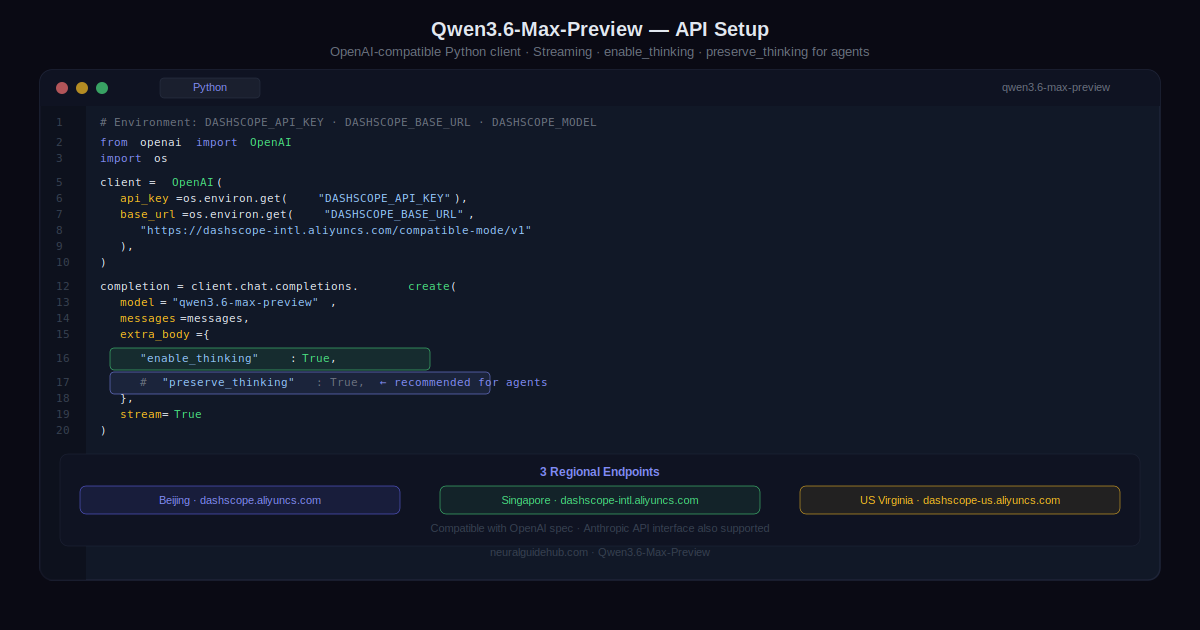
The model is available now on Qwen Studio for interactive use. The API via Alibaba Cloud Model Studio is coming soon under the model name qwen3.6-max-preview. The API supports OpenAI-compatible chat completions and responses endpoints, plus an Anthropic-compatible API interface.
Three regional endpoints are available once the API goes live. Beijing at dashscope.aliyuncs.com, Singapore at dashscope-intl.aliyuncs.com, and US Virginia at dashscope-us.aliyuncs.com. All use the same compatible-mode path format.
One API feature worth flagging for agentic use: the preserve_thinking parameter. This keeps thinking content from previous turns in the conversation context, which Alibaba specifically recommends for agentic tasks. If you are building multi-step workflows where the model’s reasoning chain from earlier steps is relevant to later decisions, this is the parameter that makes that work properly.
What to Expect as Development Continues
Alibaba is direct about where this model stands. It is a preview. Active development is ongoing. They expect further improvements in subsequent versions and are actively collecting community feedback.
That framing sets reasonable expectations. The benchmark numbers are strong for a model that is not yet at its final state. The coding improvements over Qwen3.6-Plus are substantial enough that teams running agentic coding pipelines should test it now rather than waiting for the final release. Real-world feedback during preview is exactly what makes subsequent versions better.
For teams evaluating frontier models for production coding agents, the SWE-bench Pro lead over Claude Opus 4.6 is the headline result. Combined with the SkillsBench jump and the instruction following improvements, this is a model that has moved meaningfully forward on the dimensions that matter most for agent reliability. The fact that it is still being iterated on makes it more interesting to watch, not less.