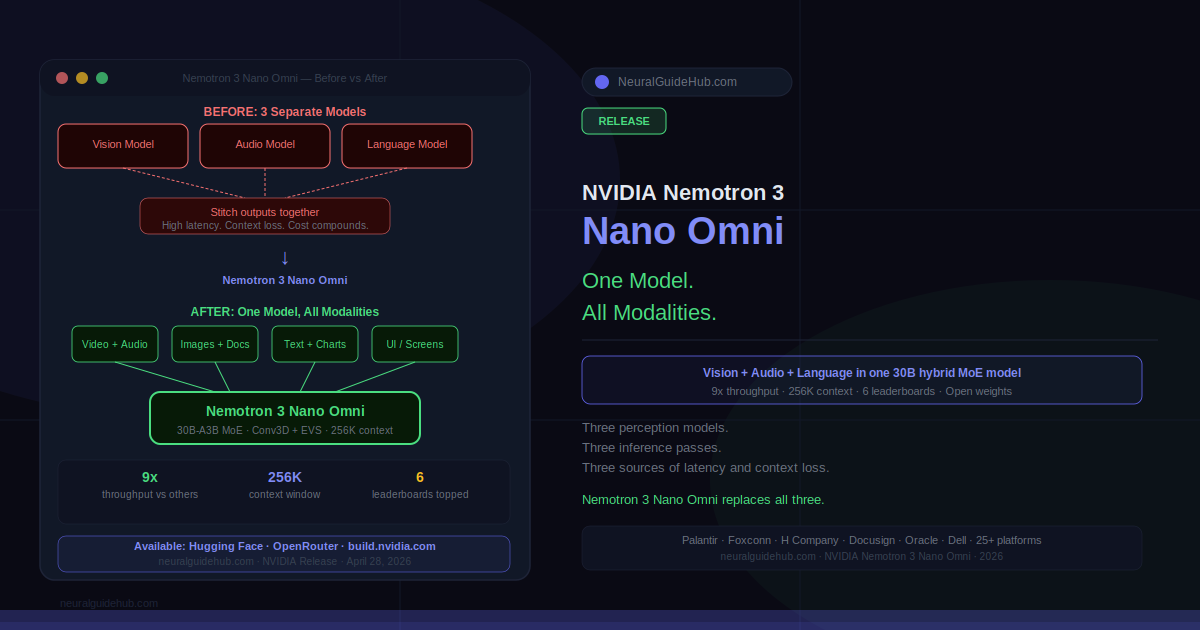
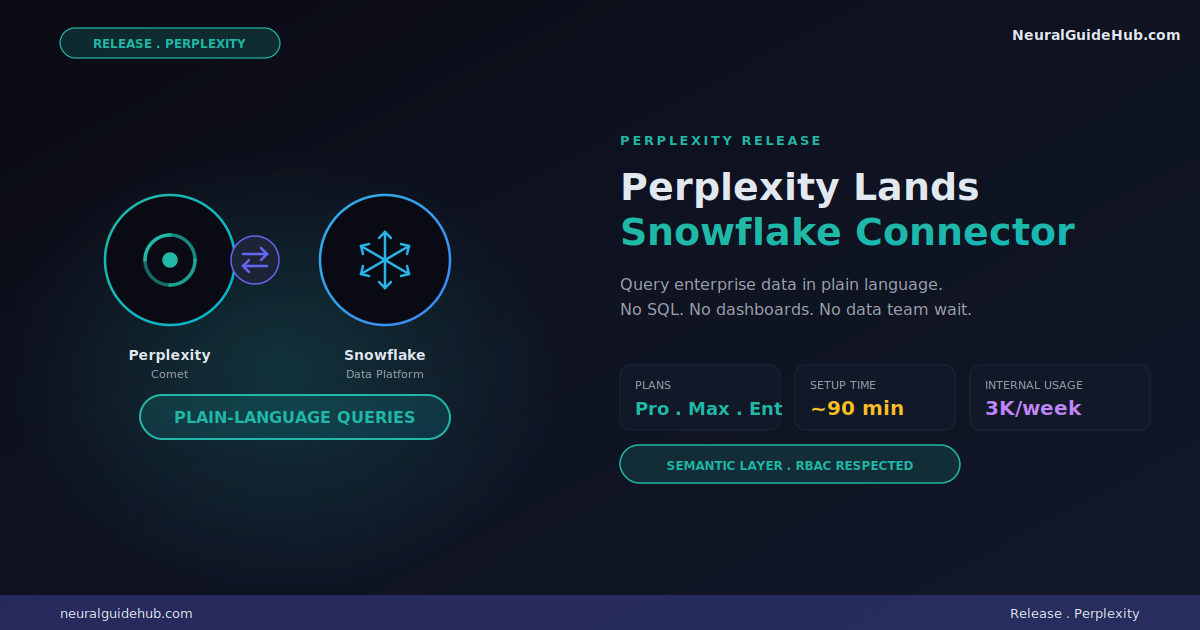
Perplexity shipped a Snowflake connector. Took them a while. The Perplexity Snowflake connector lets anyone ask Comet a question and pull data straight from Snowflake. No SQL. No ticket to the data team. No three-day wait. For most companies this is the friction that’s been blocking analytics for years.
Hundreds of Fortune 500 companies run on Snowflake. The data sits there, locked behind queries most people can’t write. Now they can just ask.
How it works
Connect Snowflake. Done. Then ask things. “Top drivers of support tickets this quarter?” “Forecast demand for the next eight weeks?” Comet hits Snowflake. Runs the query. Returns the answer.
That’s it. The whole flow.
RBAC stays in place. Admins still pick which databases, schemas, and tables anyone can touch. Read-only is the default suggestion. Data doesn’t train models.
The semantic layer is the trick
Most natural-language SQL tools break the same way. They turn words into queries without knowing the business. Output: technically valid SQL that returns the wrong number.
Perplexity got around this with a shared semantic layer. The data team defines what matters. Which tables. What the metrics mean. How questions map to SQL. The system learns the company’s logic first. Then users ask things.
Not exciting on its own. But it’s the difference between a demo and a tool people actually use.

Built from their own usage
This started as an internal Slackbot at Perplexity. Employees asked Snowflake things in plain English. Product. Growth. Support. Security. Everyone.
3,000 queries a week now. Real ones. “How does our launch calendar map to subscription growth?” “Top AI models picked for finance queries?”
This matters more than it sounds. Most enterprise tools get built top-down. This one shipped after the internal version was already doing real work. Different starting point.
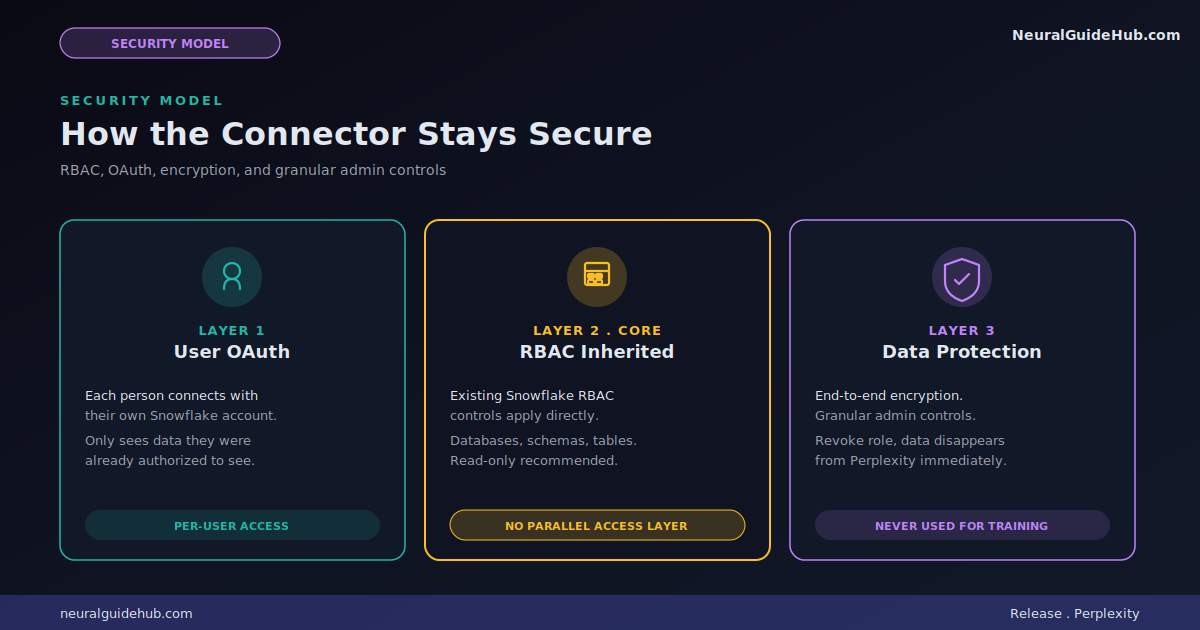
Security model
This is the part security teams will scrutinize.
User OAuth. Each person hooks up their own Snowflake account. They only see what they were already allowed to see. Drop their role and the data drops from Perplexity instantly.
Encryption. Granular access. The connector inherits existing Snowflake controls. Doesn’t build a parallel access path. Right call. Parallel access paths are how data leaks.
Why this one might actually stick
The natural-language SQL space has been crowded for two years. Most products demo well, fall apart in production. The Perplexity Snowflake connector has three things going for it.
The semantic layer carries the business context, not just the SQL translation. The integration sits inside existing Snowflake permissions instead of routing around them. And the product comes from a team that’s already running 3,000 queries on it weekly.
Most analytics tools say they’ll democratize data. They don’t, because the complexity ends up on end users. Perplexity moved the complexity into the semantic layer where it belongs.
Setup
Connect Snowflake. Open Settings then Connectors. Click “Generate data map.” Open “View knowledge” once it’s done.
Generation can take up to 90 minutes. One-time. Every query after that uses the indexed semantic layer.
Available today on Pro, Max, and Enterprise plans.
What I’d watch
Does the semantic layer scale? Hundreds of tables with inconsistent naming will stress-test this. First-time generation is fine. The maintenance loop matters more.
Accuracy on the messy domains. Sales is structured. Marketing attribution gets noisy. Operations is the worst. That’s where the connector will be judged.
Cost at scale. Pro and Max are available now. The per-query economics will decide if this becomes a casual tool or the main analytics interface.
If you’re on Snowflake, pilot it this quarter. First time a PM gets an answer in 30 seconds that used to take three days, it clicks.
https://www.perplexity.ai/hub/blog/computer-brings-data-science-to-every-team