The conversation about AI infrastructure has been almost entirely about GPUs for the past three years. Training runs. Inference clusters. H100s, B200s, TPUs. The assumption baked into most of that discussion is that GPU compute is the constraint. But agentic AI changes the workload profile in ways that are starting to show up in hardware decisions. Meta’s announcement of a large-scale agreement with AWS on Meta AWS Graviton cores is the clearest signal yet that CPU compute is becoming a serious part of the agentic AI infrastructure picture.
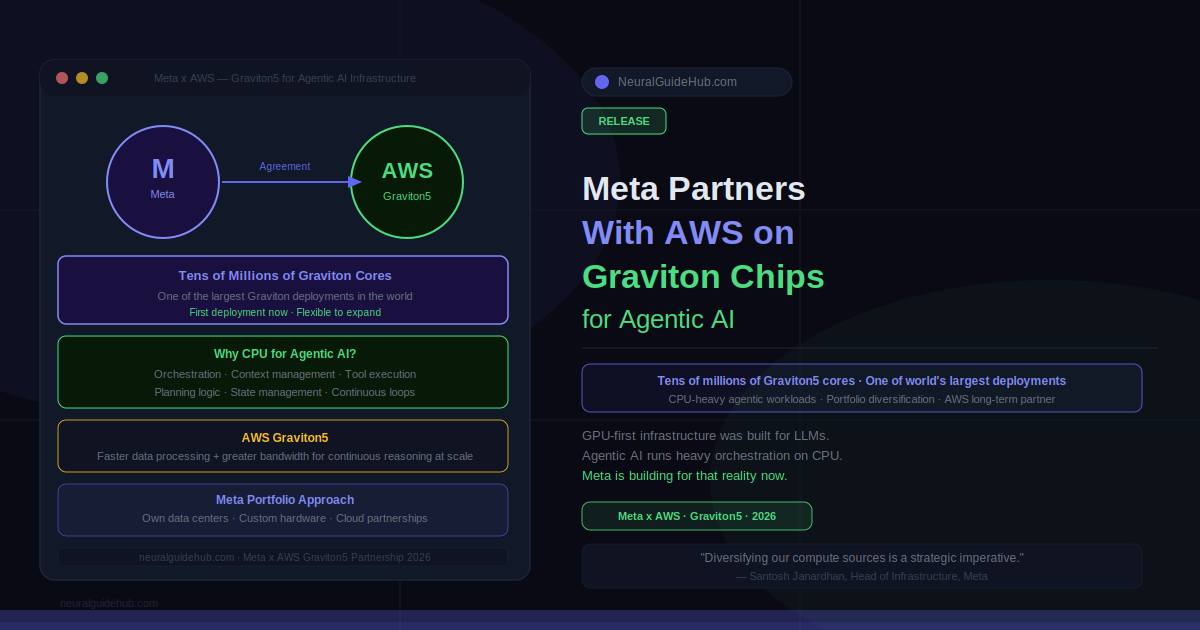
Meta is bringing tens of millions of AWS Graviton cores into its compute portfolio, making it one of the largest Graviton customers in the world. The first deployment starts at that scale, with flexibility to expand. Santosh Janardhan, Meta’s Head of Infrastructure, described adding Graviton as a response to the CPU-intensive workloads behind agentic AI. That framing is worth taking seriously.
Why Agentic AI Demands More CPU
Agentic AI systems don’t just process a prompt and return a response. They reason through problems, maintain state across multiple steps, call external tools, execute tasks, evaluate their own outputs, and repeat that loop continuously. The orchestration layer running those loops, managing context, coordinating tool calls, and maintaining task state runs on CPU. A lot of it.
GPU compute handles the model inference — the actual forward pass through the neural network. But everything around that, the routing, the memory management, the tool execution, the planning logic, runs on CPU. As agents get more capable and handle longer, more complex tasks, the CPU requirement grows proportionally. What worked as a GPU-first architecture for a chat assistant doesn’t necessarily work as well for an autonomous agent completing multi-hour workflows.
AWS Graviton5 cores offer faster data processing and greater bandwidth specifically tuned for workloads that need to continuously reason through and execute tasks at scale. That’s the product requirement that maps onto what Meta is building: AI systems that serve billions of people, running agents that need reliable, high-throughput CPU performance underneath the GPU inference layer.
Meta AWS Graviton and the Portfolio Approach to Infrastructure
Meta’s infrastructure strategy has never been single-vendor or single-architecture. They build their own data centers, develop custom hardware, and partner with cloud providers for differentiated capabilities. Adding AWS Graviton to that mix is consistent with a principle Janardhan articulated directly: building AI at Meta’s scale requires a diversified approach to infrastructure, where the right compute is matched to the right workload.
That’s not a hedge. It’s an engineering decision. GPUs are expensive and highly optimized for matrix multiplication at inference time. CPUs are better suited for the coordination, memory, and branching logic that agentic systems require in the layers above the model. Running both efficiently at scale means you need purpose-built options for each, rather than forcing one architecture to do everything.
Nafea Bshara, Vice President and Distinguished Engineer at Amazon, described the partnership as combining purpose-built silicon with the full AWS AI stack. The Graviton5 cores don’t run in isolation — they sit within an ecosystem of AWS AI services that Meta is already using through its long-standing relationship with the cloud provider. Expanding to custom silicon is an extension of that existing foundation, not a new architectural departure.
Scale and What It Means for the Industry
Tens of millions of Graviton cores is a significant number. For context, AWS Graviton cores are physically inside standard server CPUs, so the total server count is meaningfully lower than the core count. But the scale signals that Meta is not running a pilot. This is a production-scale commitment to CPU-heavy agentic infrastructure.
For the broader industry, the signal is clear. As AI workloads shift from primarily generative inference to agentic systems that reason and execute over time, the infrastructure mix shifts with them. GPU-first infrastructure built for LLM serving may need to be rebalanced as agents running on top of those models generate significant CPU overhead that wasn’t part of the original architecture plan.
Meta is one of the few organizations running AI at a scale where these infrastructure choices show up as real engineering problems rather than theoretical concerns. When Meta announces a decision to bring tens of millions of CPU cores into the agentic AI stack, it reflects a workload reality that other organizations building agents at scale will eventually hit, at whatever scale they operate.
https://about.fb.com/news/2026/04/meta-partners-with-aws-on-graviton-chips-to-power-agentic-ai