Most model releases come with a benchmark table and a blog post that says “state of the art.” You read it, note the numbers, and move on. Kimi K2.6 is a harder release to dismiss. Moonshot AI is open sourcing the weights, the coding benchmark numbers hold up under scrutiny, and the agent swarm architecture scales in ways that most competitors are not publicly demonstrating. That combination is worth paying attention to.
Kimi K2.6 is available via Kimi.com, the Kimi App, the API, and Kimi Code. It features long-horizon coding execution, coding-driven design capabilities, and an expanded agent swarm system that scales horizontally to 300 sub-agents working across 4,000 coordinated steps simultaneously. This is not an incremental update to K2.5. The architecture changes are substantive.
Long-Horizon Coding: What K2.6 Actually Proves
The coding story here is told through two specific tasks that are worth reading carefully, because they are far more demanding than standard benchmark conditions.
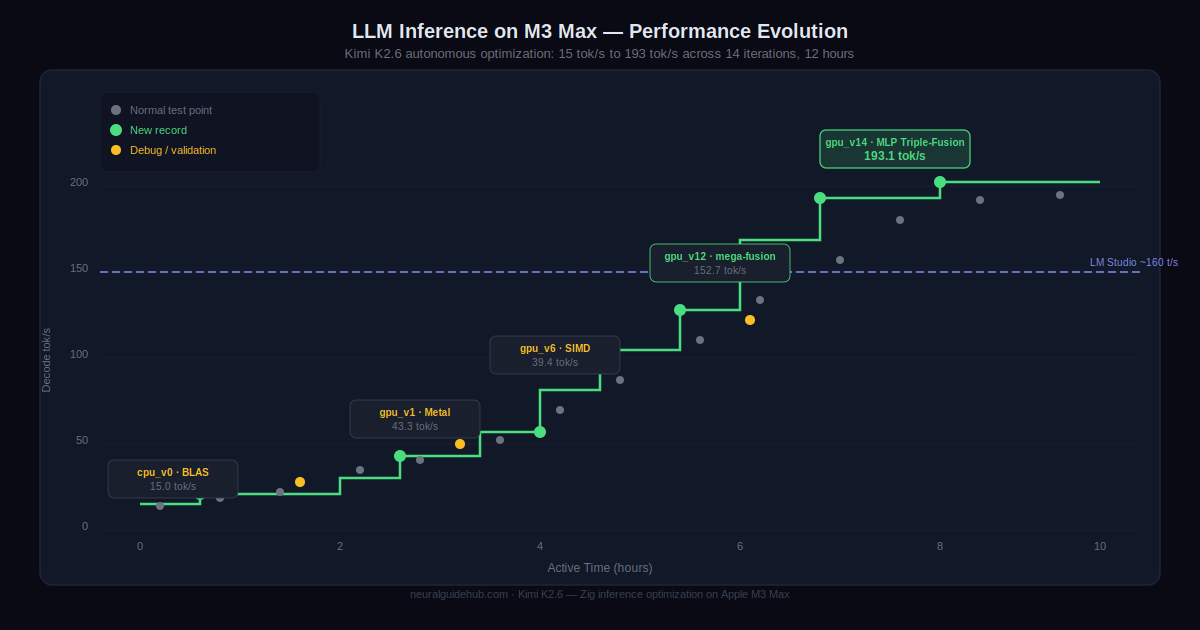
First task: K2.6 downloaded and deployed the Qwen3.5-0.8B model locally on a Mac, then implemented and optimized model inference in Zig, a programming language that sits well outside the training distribution of most frontier models. Over 4,000+ tool calls, 12 hours of continuous execution, and 14 iteration rounds, it improved throughput from roughly 15 tokens per second to 193 tokens per second. That final number is approximately 20% faster than LM Studio on the same hardware. The model did not just write code. It debugged, iterated, profiled, and optimized across a full engineering cycle.
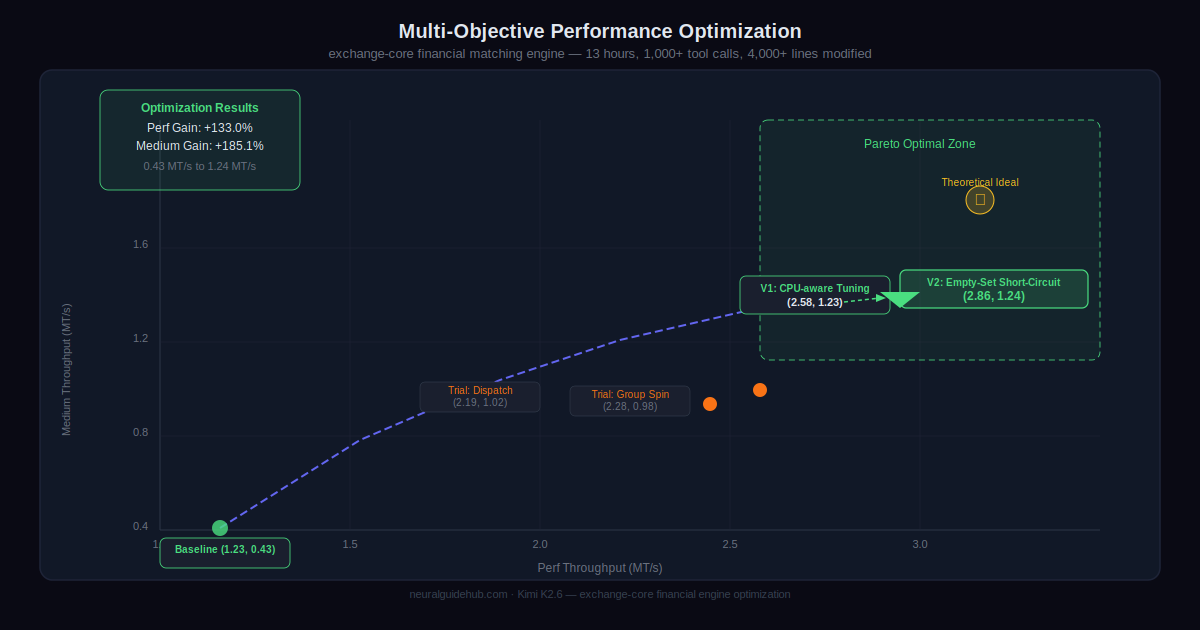
Second task: K2.6 autonomously overhauled exchange-core, an 8-year-old open-source financial matching engine. Over 13 hours, the model worked through 12 optimization strategies, made over 1,000 tool calls, and modified more than 4,000 lines of code. It analyzed CPU and memory allocation flame graphs to identify hidden bottlenecks, then made a bold architectural decision: reconfiguring the core thread topology from 4ME+2RE to 2ME+1RE. The result was a 185% medium throughput improvement and a 133% peak throughput gain on a system that was already operating near its performance limits.
These are not toy problems. An 8-year-old production codebase with flame graph analysis and topology decisions is exactly the kind of task that separates real agentic coding capability from prompted code generation.
Coding-Driven Design and Full-Stack Capabilities
Beyond backend engineering, K2.6 brings strong frontend design generation from simple prompts. It generates structured layouts with deliberate aesthetic choices including hero sections, scroll-triggered animations, and interactive elements. Not just static HTML. Actual working interfaces with visual coherence.
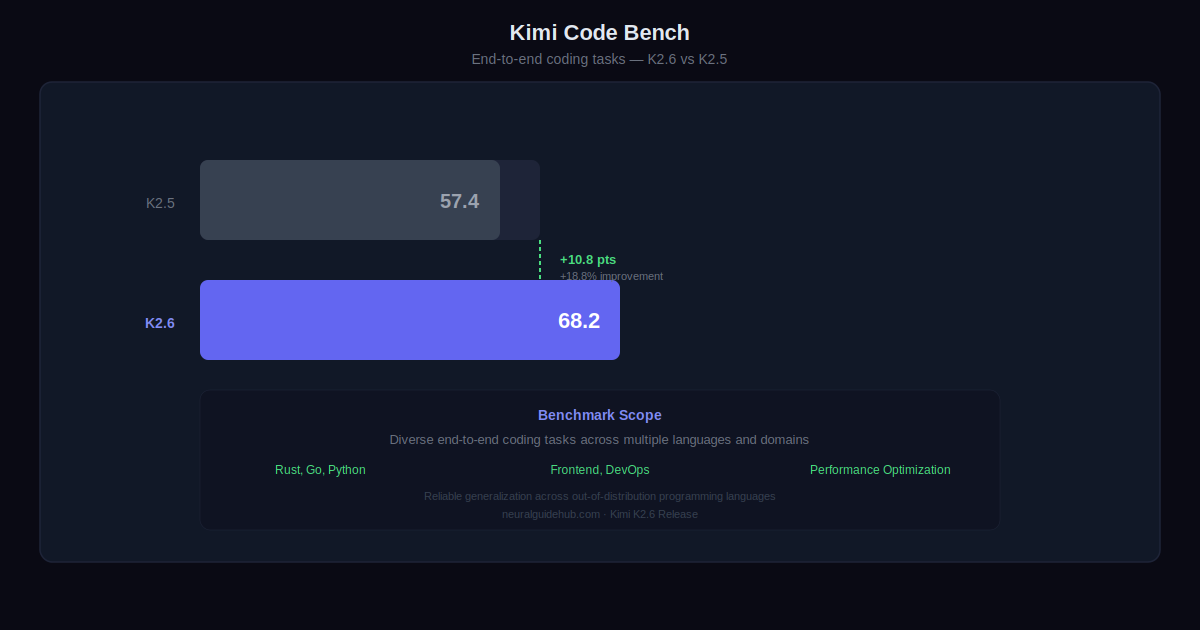
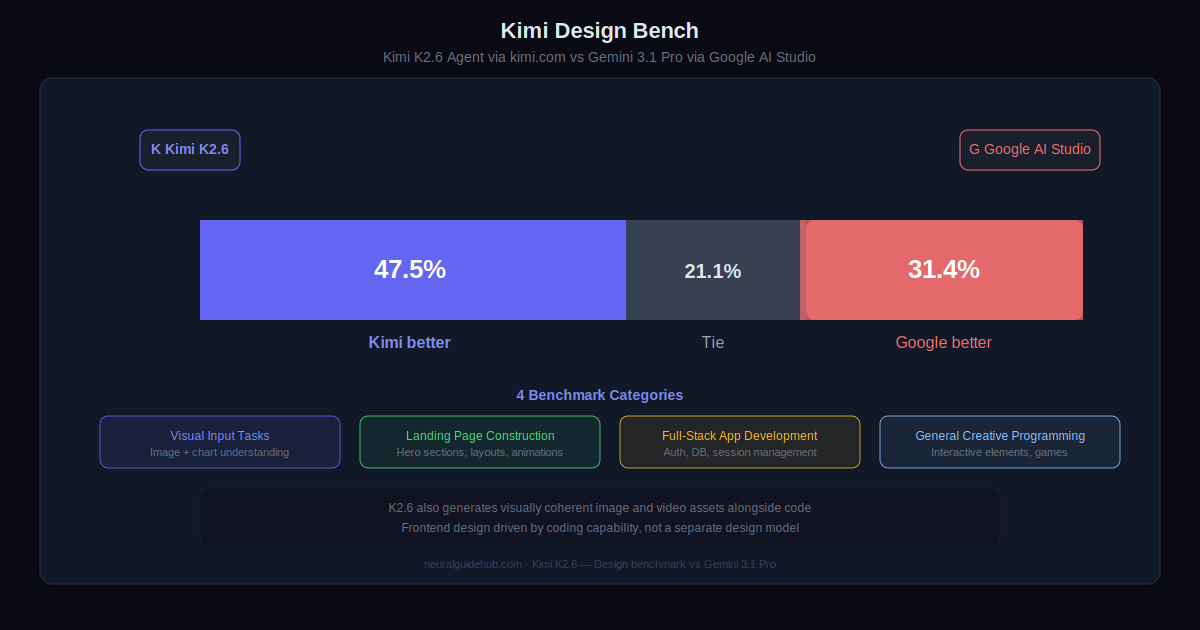
The model also supports image and video generation tool integration, which means it can produce visually coherent assets alongside the code that displays them. For frontend and full-stack prototyping, this closes the loop between design and implementation in a single workflow.K2.6 also expands into lightweight full-stack development, covering authentication flows, user interaction handling, and database operations for use cases like transaction logging and session management. Kimi Design Bench compared K2.6 against Gemini 3.1 Pro via Google AI Studio across four categories: Visual Input Tasks, Landing Page Construction, Full-Stack Application Development, and General Creative Programming. K2.6 wins 47.5% of tasks, ties on 21.1%, and loses 31.4%.
Agent Swarms: 300 Sub-Agents, 4,000 Steps
The agent swarm architecture is where K2.6 makes its most significant architectural claim. The system dynamically decomposes complex tasks into subtasks executed concurrently by self-created domain-specialized agents. K2.5 supported 100 sub-agents across 1,500 coordinated steps. K2.6 scales that to 300 sub-agents across 4,000 steps simultaneously.
The practical output of a K2.6 swarm run can include full documents, websites, slide decks, and spreadsheets generated in a single autonomous pass. The swarm combines broad web search with deep research, large-scale document analysis with long-form writing, and multi-format content generation in parallel. That compositional intelligence is the part most agentic systems are still struggling to demonstrate reliably.
Moonshot also introduced Claw Groups in research preview, an extension of the swarm architecture to open heterogeneous ecosystems. Multiple agents and humans operate as collaborators. Users can onboard agents from any device, running any model, each with their own specialized toolkits, skills, and persistent memory. K2.6 serves as the adaptive coordinator, matching tasks to agents based on skill profiles, detecting failures, and managing the full lifecycle from initiation to validation.
Benchmark Results vs GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro
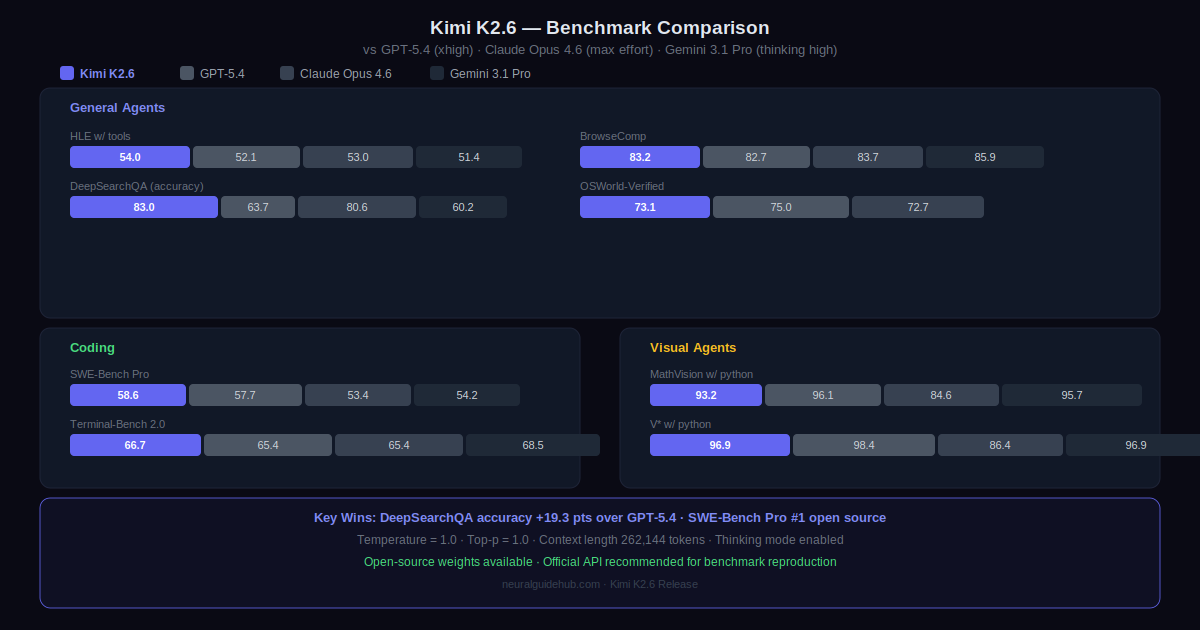
The benchmark table covers agentic, coding, reasoning, and vision categories. A few numbers worth highlighting from the comparison against GPT-5.4 (xhigh), Claude Opus 4.6 (max effort), and Gemini 3.1 Pro (thinking high):
On SWE-Bench Pro, K2.6 scores 58.6 versus GPT-5.4 at 57.7 and Claude Opus 4.6 at 53.4. On DeepSearchQA accuracy, K2.6 reaches 83.0 against GPT-5.4’s 63.7. On SWE-Bench Multilingual, K2.6 scores 76.7 against Gemini’s 76.9 and Claude’s 77.8. On LiveCodeBench v6, K2.6 scores 89.6 versus Claude Opus 4.6 at 88.8.
The vision benchmarks show a more mixed picture. On MathVision with Python, K2.6 reaches 93.2% versus Gemini at 95.7% and GPT-5.4 at 96.1%. On BabyVision, K2.6 scores 39.8 versus GPT-5.4 at 49.7 and Gemini at 51.6. Vision is not K2.6’s strongest category, and the numbers reflect that honestly.
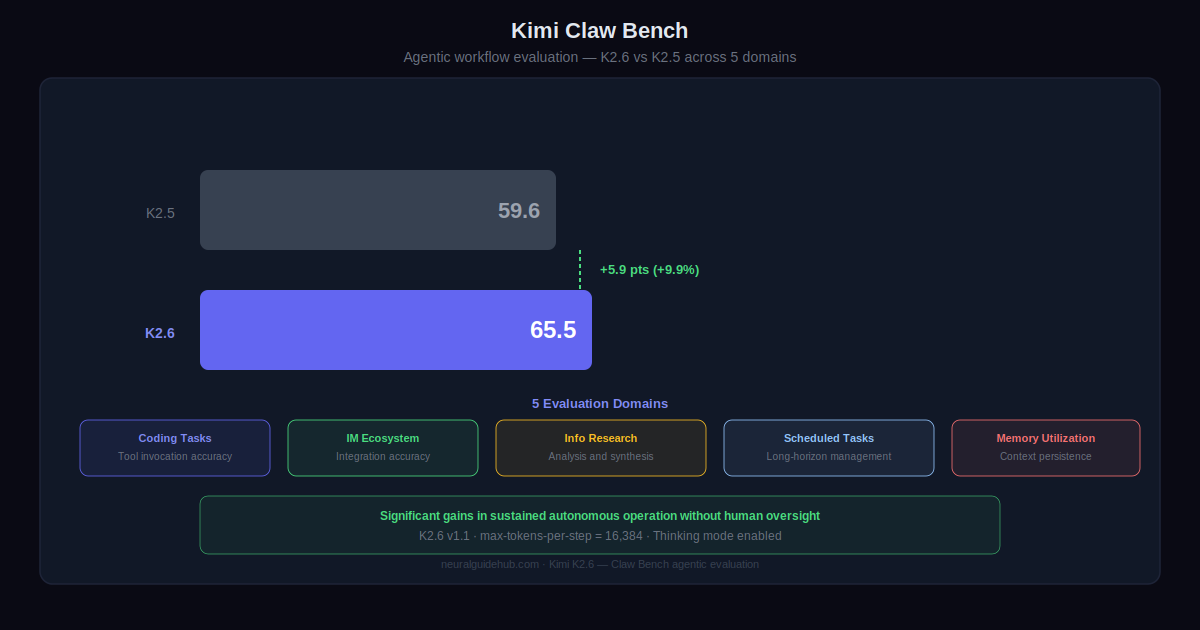
Kimi K2.6 is available now via Kimi.com, the Kimi App, the Kimi API, and Kimi Code. Model weights are open sourced. Moonshot recommends using the official API to reproduce benchmark results, and provides Kimi Vendor Verifier (KVV) for evaluating third-party provider accuracy before committing to a deployment choice.
For teams evaluating open-source frontier models for production coding agents, the combination of open weights, strong SWE-Bench Pro performance, and demonstrated long-horizon execution capability makes K2.6 a serious candidate. The vision benchmarks lag, and the swarm capabilities are still in research preview for the most advanced features. But on raw coding agent performance, this is one of the most competitive open-source releases available right now.