Cost is the argument that keeps open-source AI competitive with closed models. Not just benchmark numbers. Not just parameter counts. The actual dollar cost of running inference at scale, which is where most frontier models quietly become impractical for smaller teams and startups. DeepSeek V4 launched this week with a pricing structure and context efficiency architecture that makes that argument more forcefully than anything the open-source ecosystem has produced before.
Two models. DeepSeek-V4-Pro: 1.6 trillion total parameters, 49 billion active, 33 trillion pre-trained tokens, 1 million token context window. DeepSeek-V4-Flash: 284 billion total parameters, 13 billion active, 32 trillion pre-trained tokens, same 1 million context window. Both are fully open-sourced with weights on Hugging Face. Both are available via API today.
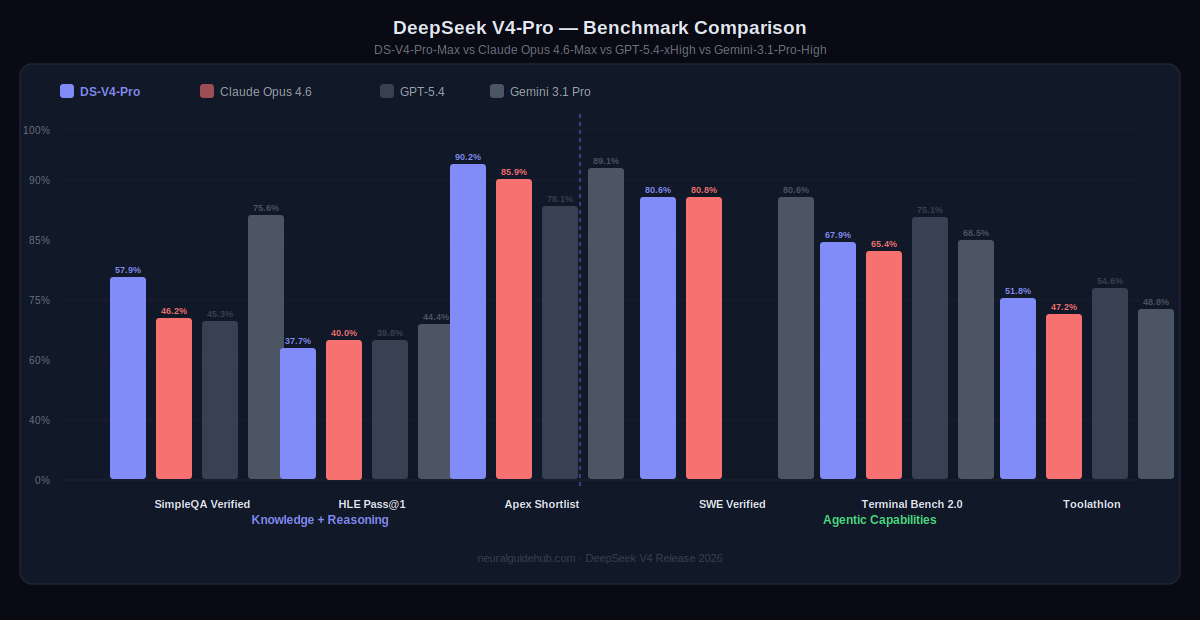
DeepSeek V4 Benchmark Results
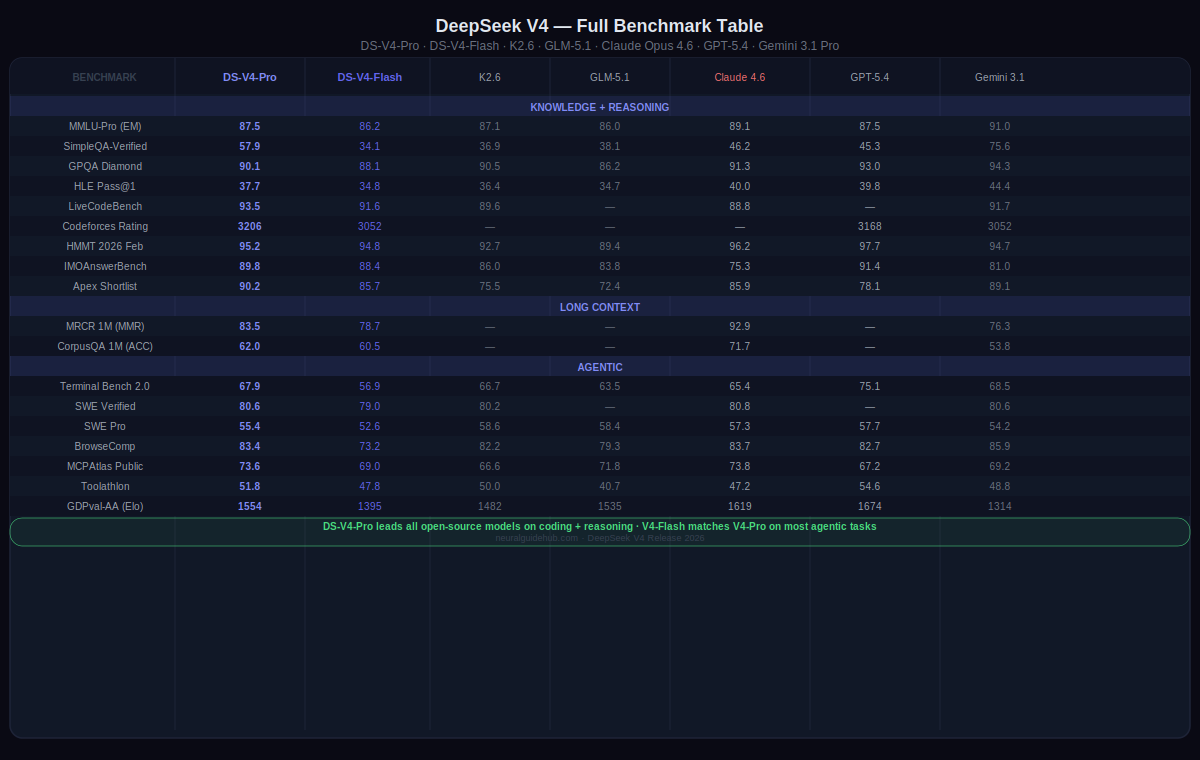
The coding numbers are where V4-Pro makes its clearest statement. On Codeforces, it scores 3206 — above GPT-5.4 xHigh at 3168 and Gemini-3.1-Pro-High at 3052. On LiveCodeBench, it scores 93.5 versus Claude Opus 4.6 Max at 88.8 and Gemini at 91.7. On SWE-Verified, it matches Claude at 80.6 and ties Gemini at 80.6. These are not cherry-picked categories. They represent the full range of agentic coding evaluation.
On IMOAnswerBench for mathematical reasoning, V4-Pro scores 89.8. GPT-5.4 scores 91.4. Claude Opus 4.6 scores 75.3. Gemini scores 81.0. On HMMT 2026 February, V4-Pro scores 95.2 versus GPT-5.4’s 97.7 and Claude’s 96.2. The knowledge and reasoning benchmarks place V4-Pro clearly among the top closed-source models, not below them.
V4-Flash, the smaller model, holds up better than you’d expect given its size. On Apex Shortlist it scores 85.7. On SWE-Verified it reaches 79.0. On GPQA Diamond it scores 88.1 versus V4-Pro’s 90.1. For workloads that don’t need the full V4-Pro capability, Flash covers most of the ground at significantly lower cost and faster response times.
The Architecture Behind DeepSeek V4’s Context Efficiency
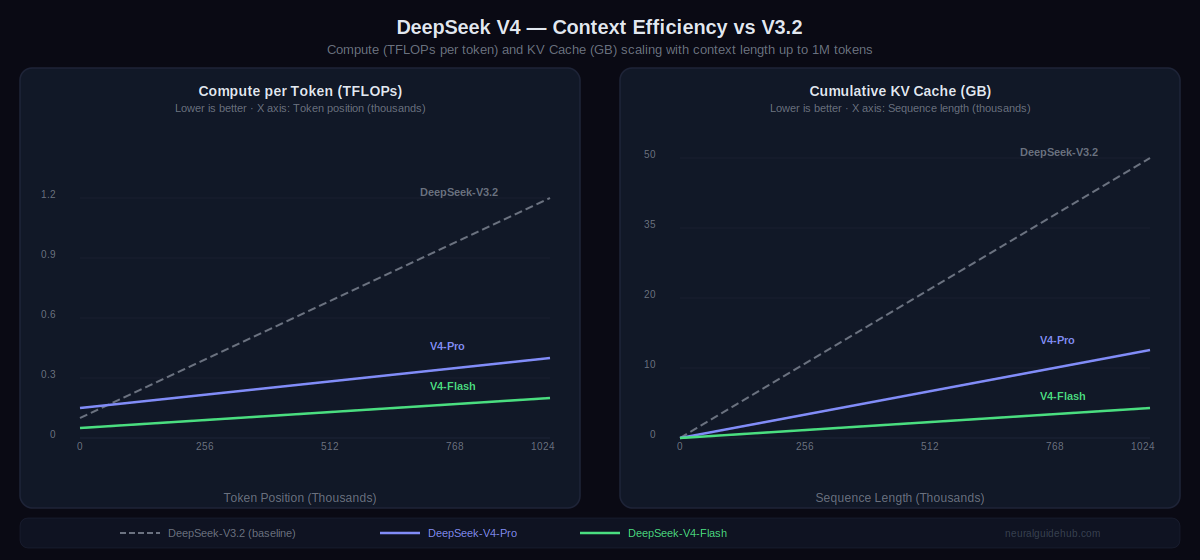
One million token context is the default across all official DeepSeek services now. Not a premium tier. Not a separate API endpoint. The standard. Getting there without making inference prohibitively expensive required architectural work that goes beyond standard attention mechanisms.
DeepSeek V4 introduces token-wise compression combined with DSA (DeepSeek Sparse Attention). The effect shows up in the compute and memory cost curves as context length increases. V3.2 scales linearly in both TFLOPs per token and KV cache memory requirements as you extend context. V4-Pro stays dramatically flatter. V4-Flash is even lower. At 1 million tokens, the difference between V3.2 and V4-Pro in cumulative KV cache size is roughly 10x. That’s not a marginal improvement. That’s the difference between 1M context being practical and 1M context being a cost that most deployments can’t absorb.
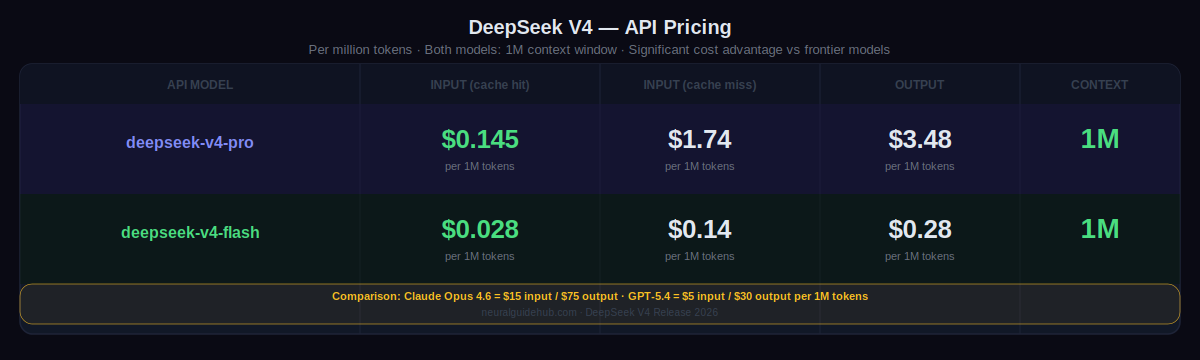
Pricing: Where DeepSeek V4 Changes the Conversation
V4-Pro API pricing: $0.145 per million tokens on cache hit input, $1.74 on cache miss input, $3.48 on output. V4-Flash: $0.028 cache hit input, $0.14 cache miss input, $0.28 output. Both with 1 million token context.
For comparison: Claude Opus 4.6 runs at $15 per million input tokens and $75 per million output tokens. GPT-5.4 at $5 input and $30 output. Gemini 3.1 Pro at comparable tiers. V4-Pro at $1.74 input and $3.48 output represents a roughly 4-10x cost reduction depending on the competitor. V4-Flash at $0.14 input and $0.28 output is in a different category entirely for high-volume applications.
That pricing structure, combined with open weights, changes the calculus for any team evaluating whether to build on a closed frontier model or invest in self-hosting. The benchmark gap is small enough that the cost difference dominates the decision for most use cases.
Model Specs and Access
Both models are available now. API access uses the existing DeepSeek base URL — just update the model parameter to deepseek-v4-pro or deepseek-v4-flash. The API supports both OpenAI ChatCompletions and Anthropic API formats. Both models support Thinking and Non-Thinking modes with the 1M context window.
Important for existing users: deepseek-chat and deepseek-reasoner will be retired and inaccessible after July 24th, 2026 at 15:59 UTC. They are currently routing to V4-Flash non-thinking and thinking respectively, but the old model names will stop working at that date.
On the web interface at chat.deepseek.com, V4-Pro runs in Expert Mode and V4-Flash runs in Instant Mode. Open weights are available on Hugging Face for self-hosting. DeepSeek V4-Pro is already integrated with Claude Code, OpenClaw, and OpenCode for agentic coding workflows.