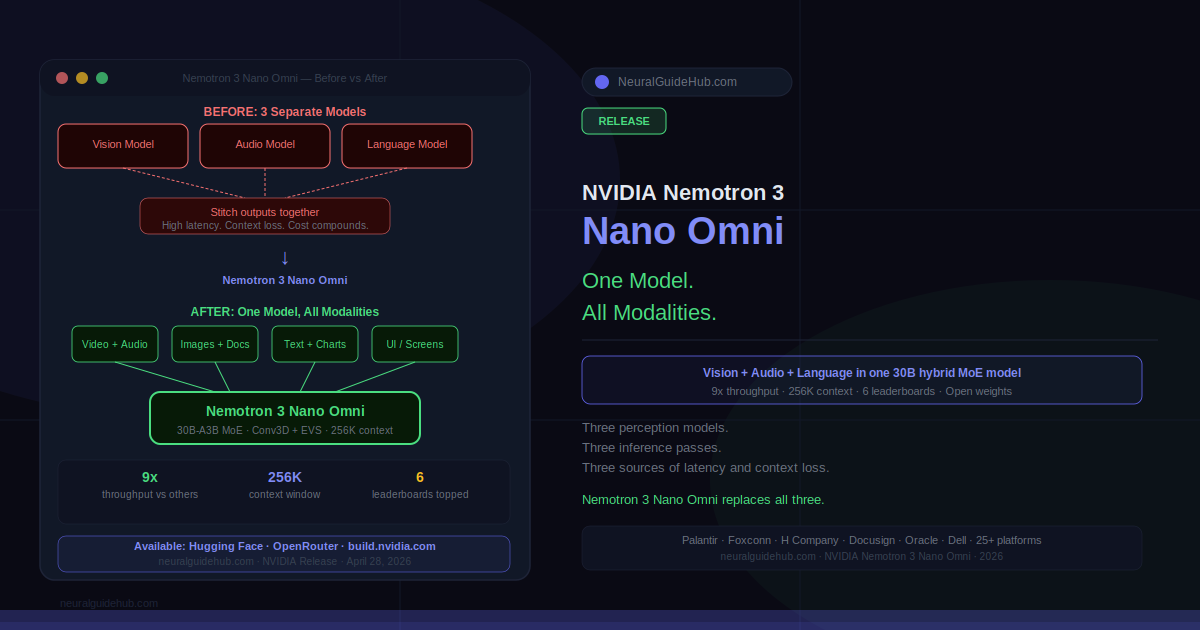
Here’s a problem most AI agent demos don’t show you. The agent gets a screen recording, passes it to a vision model. Gets an audio clip, passes it to a speech model. Gets a document, passes it to a language model. Each handoff takes time. Each handoff loses context. By the time all three outputs arrive and get stitched together, you’ve introduced latency, cost, and the kind of subtle inaccuracies that compound when an agent runs hundreds of these cycles per day. Nemotron 3 Nano Omni is NVIDIA’s answer to that specific problem: one model, all three modalities, no handoffs.
Released today on Hugging Face, OpenRouter, and build.nvidia.com, it’s a 30B-parameter hybrid mixture-of-experts model with a 256K context window. It handles text, images, audio, video, documents, charts, and graphical interfaces as input. It tops six leaderboards for document intelligence, video understanding, and audio understanding. And according to NVIDIA, it delivers 9x higher throughput than other open omni models with comparable interactivity.
Why the Architecture Decision Matters
Most multimodal agent systems today are actually several models running in sequence. Vision model for screen content. Speech model for audio. Language model for reasoning and output. That pipeline works but it has real costs. Every inference pass adds latency. Context gets fragmented as outputs get summarized and passed between models. Errors accumulate.
Nemotron 3 Nano Omni collapses that pipeline. It uses a hybrid MoE architecture with Conv3D and EVS encoders that handle vision and audio natively, inside the same model that does language reasoning. The result is that an agent processing a screen recording, a voice note, and a PDF simultaneously doesn’t need three models and three inference passes. It needs one.
Gautier Cloix, CEO of H Company, was direct about what this unlocks practically: “To build useful agents, you can’t wait seconds for a model to interpret a screen.” H Company is running Nemotron 3 Nano Omni at native 1920×1080 resolution for their computer use agents. In preliminary OSWorld benchmark evaluations, they saw a significant improvement in navigating complex graphical interfaces. That’s not a marginal gain — high-resolution visual reasoning at that throughput level wasn’t practical before this model.
Three Things Nemotron 3 Nano Omni Is Actually Built For
Computer use agents. Navigating graphical interfaces, reading screen state, reasoning over UI elements in real time. H Company’s agent use case is the concrete example here — full HD screen recording, processed natively, without downsampling or external vision preprocessing.
Document intelligence. Not just text extraction. Interpreting visual structure in documents — charts, tables, mixed-media layouts, screenshots embedded in reports. Enterprise compliance and analysis workflows where you need to reason across visual and textual content coherently in one pass.
Audio and video understanding. Customer service, research monitoring, media analysis. The model maintains audio-video context across a single reasoning stream rather than producing disconnected summaries from separate models. What was said, what was shown, what was documented — all in one inference.
How Nemotron 3 Nano Omni Fits Into a Larger Agent System
NVIDIA positions this as the perception sub-agent in a multi-model system. The “eyes and ears” framing is accurate. Nemotron 3 Nano Omni handles what the agent sees and hears. For reasoning and planning at higher complexity levels, it works alongside Nemotron 3 Super for high-frequency execution and Nemotron 3 Ultra for complex planning. It also integrates with proprietary models from other providers.
That composability is the practical deployment story. You’re not replacing your entire agent stack with this one model. You’re replacing the fragmented perception layer — the three separate models handling vision, audio, and language inputs — with one that does all three with better throughput and less latency.
Who Is Already Using It
The adoption list at launch is worth noting. Aible, Applied Scientific Intelligence, Eka Care, Foxconn, H Company, Palantir, and Pyler are already building on it. Dell Technologies, Docusign, Infosys, Oracle, and Zefr are evaluating. That’s a mix of enterprise software, healthcare, manufacturing, and defense — not a homogeneous category. The breadth suggests the use case is genuinely broad rather than narrow.
The Nemotron family has crossed 50 million downloads over the past year. The Nano Omni extends the family into multimodal and agentic territory, which is where most of the interesting enterprise deployment is happening right now.
Deployment and Availability
Open weights, open datasets, open training techniques. Full transparency for organizations that need it, which covers most regulated industries. Deployable on NVIDIA Jetson hardware for edge cases, DGX Spark and DGX Station for workstation deployments, and full data center and cloud environments for scale. The 256K context window holds up across all of those deployment targets.
Available today via Hugging Face, OpenRouter, build.nvidia.com as an NVIDIA NIM microservice, and across 25+ partner platforms. For organizations with data localization or sovereignty requirements, the open architecture means you can run it entirely on your own infrastructure without calling home to a cloud API.
The 9x throughput claim over comparable open omni models is the number that will get tested in production over the next few months. If it holds at the scale H Company, Palantir, and Foxconn operate at, the efficiency case for replacing fragmented perception pipelines with Nemotron 3 Nano Omni becomes very difficult to argue against.
https://blogs.nvidia.com/blog/nemotron-3-nano-omni-multimodal-ai-agents/