
Voice AI has been sitting in the “promising but not quite there yet” category for years. That era is ending. Google’s Gemini 3.1 Flash Live represents one of the most significant technical leaps we’ve seen in this space not just a faster or cheaper model, but an architectural shift that redefines what human machine voice interaction can actually look like in production.
In this piece, we break down the model’s technical foundation, what it genuinely offers developers, and where it sits in the broader landscape of voice AI from the perspective of someone who builds with these systems.
Why Voice AI Is So Hard to Get Right
Understanding text and understanding speech are fundamentally different problems. Text is static. Speech is a continuous, noise filled, context dependent data stream. Users pause mid-sentence, backtrack, get interrupted, speak over background noise, and convey meaning not just through words but through pitch, pace, and emphasis.
Traditional approaches handled this with a three step pipeline: speech-to-text, language model processing, text-to-speech. Every link in that chain introduces latency and compounds errors. Gemini 3.1 Flash Live breaks the chain entirely. It’s a native audio-to-audio model speech goes in, processed audio comes back out, with no intermediate text layer degrading the experience.
The Numbers: What the Benchmarks Actually Tell Us
Marketing claims are easy to make. Benchmark results are harder to fake.
ComplexFuncBench Audio measures multi step function calling accuracy in live audio environments. It simulates real-world agentic scenarios: a user makes a request, the system must understand it and trigger one or more external tools in sequence, then deliver the result conversationally. Here’s how the models stack up:
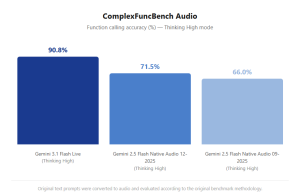
That 27-point gap over the previous generation isn’t just a number on a leaderboard. In production terms, it translates directly to fewer failed task completions, fewer confused users, and fewer fallback-to-human escalations in automated pipelines.
Scale AI’s Audio MultiChallenge tests something different and arguably more important: long-horizon reasoning under realistic conversational conditions. Interruptions, hesitations, incomplete sentences, ambient noise. The test specifically replicates the kind of messy, real-world audio that most voice systems quietly fall apart on. With thinking enabled, Gemini 3.1 Flash Live leads with a score of 36.1%.
The Technical Core: Tonal Understanding at Scale
What separates this model architecturally isn’t just speed. It’s acoustic intelligence. The model processes pitch, speaking rate, emphasis patterns, and micro-pauses as first-class input signals not as noise to be filtered out.
In practice, this means the system can detect frustration in a user’s voice and soften its response. It can recognize confusion and shift into a more step-by-step explanatory mode without being explicitly told to do so. It can identify when a user is speaking casually versus when they’re giving a precise instruction that requires careful execution.
This capability is particularly consequential in the enterprise customer experience context. A voice agent that responds not just to what a customer says, but to how they say it, operates in an entirely different tier of user experience than anything we’ve built before.
What Developers Can Actually Build
Translating technical capability into product thinking:
Intelligent voice customer service agents that adapt tone dynamically softening when a customer is upset, slowing down when they’re confused, escalating appropriately when the situation requires it. Verizon and The Home Depot have already integrated the model into their workflows and reported measurable improvements in conversational quality.
Real time multilingual assistants backed by support for more than 90 languages. Whether you’re building for a global SaaS product, an international call center, or a consumer app targeting non-English markets, the language coverage makes this a serious production option.
Voice-controlled developer tooling. Stitch used the Live API to let users design interfaces with their voice — the agent sees the canvas, understands design intent, and executes changes in real time. This is a preview of where developer tooling is heading.
Accessibility-first products. Ato, an AI companion designed for older adults, uses the model’s multilingual capabilities to turn daily conversations into genuine connection. It’s a use case that doesn’t make headlines but represents some of the most meaningful work being done with this technology.
Thinking Levels: Engineering the Latency-Intelligence Tradeoff
Every voice AI team faces the same fundamental tradeoff: deeper reasoning takes more time, and time is the enemy of natural conversation. Gemini 3.1 Flash Live makes this tradeoff explicitly configurable via the thinkingLevel parameter.
The four levels minimal, low, medium, and high give developers direct control over where a specific deployment sits on the speed-accuracy curve. The default is minimal because for most conversational interactions, response latency matters more than extended deliberation. For complex agentic tasks where accuracy is non-negotiable, high is available. This kind of per-deployment configurability is what mature production infrastructure looks like.
Security by Design: SynthID Audio Watermarking
Every audio output generated by the model is watermarked with SynthID an imperceptible, mathematically embedded signal woven directly into the audio waveform. It doesn’t degrade audio quality. It doesn’t change the listening experience. But it makes AI-generated audio reliably detectable.
In an environment where synthetic voice content is increasingly used for misinformation and fraud, this isn’t a minor feature. It’s a foundational trust mechanism. Any platform deploying voice AI at scale should be thinking about provenance and SynthID gives developers a built-in answer to that question.
Gemini 3.1 Flash Live is a concrete signal that voice AI is entering its maturity phase. The audio-to-audio architecture eliminates the latency tax of pipeline-based systems. The tonal understanding capability lifts the ceiling on what emotionally intelligent voice agents can do. The 90.8% function-calling accuracy on ComplexFuncBench represents a meaningful reliability threshold for production agentic systems.
Voice AI hasn’t reached its full potential yet. But Gemini 3.1 Flash Live is among the clearest indicators we’ve seen that the gap between “promising demo” and “production-ready infrastructure” is finally closing. Preview access is available today through Google AI Studio.