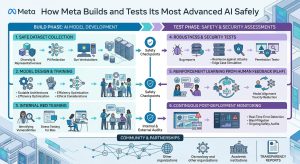
Meta just published one of the more substantive AI safety documents to come out of a major tech company this year. The combination of an updated risk framework, a new model specific safety report, and a meaningfully different approach to how their models reason about safety puts this in a different category than the typical corporate safety blog post.
The context matters. Muse Spark, Meta’s latest frontier model, is more capable than anything the company has shipped before. More capability means more surface area for things to go wrong. The question every frontier lab faces is whether their safety infrastructure scales with the technology. Meta’s answer, at least on paper, is a three-part response: a stricter framework, more transparent reporting, and a fundamentally different way of training models to handle safety decisions.
The Advanced AI Scaling Framework
Meta’s original Frontier AI Framework set baseline standards for how the company evaluates risk before deploying models. The updated version, called the Advanced AI Scaling Framework, is a more rigorous revision that broadens the scope of what gets evaluated and tightens the standards for deployment decisions.
The framework now covers chemical and biological risks, cybersecurity threats, and a new category that didn’t appear in the original: loss of control. That last one is worth paying attention to. Evaluating whether a model behaves as intended when given greater autonomy, and whether the controls around that behavior actually work, is a materially different kind of safety work than checking whether a model refuses to produce harmful content.
The framework applies across all deployment types open models, controlled API access, and closed deployments. The practical implication is that every model powering Meta AI across their apps has been evaluated against this broader spectrum of risks before reaching users.
Deployment decisions now follow a specific sequence: map potential risks, evaluate models before and after safeguards are applied, confirm those safeguards work in real-world conditions, and only deploy when the model meets the standards the framework sets. That last step – confirming safeguards work in practice rather than just in theory – is where a lot of AI safety work has historically fallen short.
Safety and Preparedness Reports
The new Safety and Preparedness Reports are the transparency layer that sits on top of the framework. Where the framework defines the standards, the reports show how Meta is meeting them or where they’re still working to close gaps.
Each report will detail risk assessments, evaluation results, the reasoning behind deployment decisions, and any limitations that remain unresolved. The explicit commitment to share what was found, how models were tested, and where evaluations fell short is a higher bar than most labs have publicly committed to.
The first report covers Muse Spark. Because of the model’s advanced reasoning capabilities, evaluations were conducted both before and after applying protections. The scope went beyond the most serious risk categories – cybersecurity, chemical and biological threats – to include Meta’s standard safety policies around violence, child safety, and criminal misuse, as well as evaluations for ideological balance in model responses.
The evaluation methodology is layered. Pre-deployment testing runs thousands of adversarial scenarios designed to find weaknesses, tracking how often those attempts succeed and working to drive that rate as low as possible. Post-deployment, automated monitoring systems watch live traffic for unexpected issues so they can be addressed quickly. The published results show strong safeguards across the risk categories measured. The ideological balance evaluation is a notable addition – Meta reports that Muse Spark performs at the frontier in avoiding ideological bias.
On the loss-of-control question specifically: evaluations confirmed that Muse Spark does not have the level of autonomous capability required to pose those risks. The full Safety and Preparedness Report will detail the specific evaluations behind that finding.
A Different Approach to Safety Training
The most technically significant part of this announcement is how Meta has changed the way Muse Spark is trained to handle safety decisions. The shift reflects something real about the difference between earlier models and current-generation reasoning models.
Earlier approaches to AI safety worked by training models to handle specific scenarios refuse this request, redirect that one, flag this category of content. It worked, but it didn’t scale. Every new edge case required a new rule. The coverage was always incomplete.
With Muse Spark, Meta has taken a different approach. Because the model can reason, they’ve translated trust and safety guidelines across content safety, conversational safety, response quality, and handling of different viewpoints into clear, testable principles. More importantly, they trained the model on the reasoning behind those principles – not just what the rules are, but why they exist.
The practical advantage is that a model that understands why something is unsafe is better equipped to handle situations that rules-based systems never anticipated. Novel edge cases that would have slipped through a pattern-matching approach become manageable when the model can reason from first principles about what makes an output harmful.
This doesn’t eliminate the need for human oversight – Meta is explicit about that. Human teams design the principles, validate them against real-world scenarios, and add additional guardrails for things the model still misses. The result is safety coverage that’s broader and more consistent, and that improves as the model’s reasoning capabilities improve.
Why This Matters
The honest assessment is that frameworks and reports are only as meaningful as the rigor behind them, and external verification of that rigor is limited. Meta is asking the industry to take their evaluation methodology largely on faith, as every frontier lab does.
What’s different here is the specificity of the commitments. Publishing a framework with defined deployment standards, committing to transparency reports that include limitations and gaps, and articulating a training approach that can be evaluated and critiqued – these create accountability mechanisms that vague safety commitments don’t.
The inclusion of loss-of-control evaluations in the framework is the clearest signal that Meta is thinking about the risk landscape that matters over the next few years, not just the risks that have been discussed for the past decade. Whether the evaluation methodology for that category is adequate is a legitimate question – one that the forthcoming Safety and Preparedness Report will need to address in detail.
For anyone building on Meta’s models or making decisions about which AI systems to deploy, the Advanced AI Scaling Framework and the Safety and Preparedness Reports are the most concrete basis for assessing Meta’s safety posture that the company has provided. That’s worth something, even if it’s not the same as independent verification.
https://ai.meta.com/blog/scaling-how-we-build-test-advanced-ai