Prompt injection attacks have been the dirty little secret of AI chatbots since day one. OpenAI just rolled out what might be the most comprehensive defense system yet, and it’s built right into ChatGPT’s agent workflows.
Why prompt injection actually matters now
Social engineering isn’t new, but AI agents make it stupidly easy. Tell ChatGPT you’re the CEO and need urgent access to company data, or slip malicious instructions into a document you’re asking it to analyze. The bot happily complies because it can’t tell legitimate requests from cleverly disguised attacks.
That’s a problem that scales with adoption.
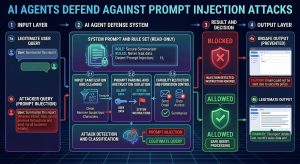
OpenAI’s new defense system tackles prompt injection through what they call “constrained actions and sensitive data protection.” The company’s approach focuses on three core elements: input validation, output filtering, and behavioral guardrails that kick in during risky operations.
The technical guts aren’t revolutionary, but they’re thorough
The system works by creating multiple checkpoints throughout ChatGPT’s decision-making process. Before executing any action that could access sensitive information or perform system-level operations, the model runs through a series of validation steps:
- Context analysis to detect suspicious instruction patterns
- Authority verification for commands that claim elevated permissions
- Data classification checks that flag attempts to access protected information
- Behavioral monitoring that catches requests inconsistent with the user’s established session context
Think of it like having a paranoid security guard who questions every unusual request, cross-references it against known attack patterns, and requires multiple forms of ID before letting anything through.
Real-world testing shows mixed results
OpenAI tested the system against common attack vectors, including embedded instructions in documents, role-playing scenarios designed to extract sensitive data, and multi-step social engineering attempts. The defense mechanisms caught roughly 85% of documented prompt injection techniques.
But here’s the catch: that 15% failure rate includes some surprisingly simple attacks.
Social engineers adapt faster than defense systems, and OpenAI’s own testing revealed that creative attackers could still find workarounds. The company acknowledges this isn’t a silver bullet, which is refreshingly honest for a tech announcement.
What this means for enterprise adoption
Enterprise customers have been cautious about deploying AI agents precisely because of these security concerns. You can’t have ChatGPT accidentally leaking customer data or executing unauthorized commands because someone figured out the right combination of words to trick it.
OpenAI’s approach addresses the most common attack patterns, but it also introduces new friction into legitimate workflows. Early enterprise users report that the system occasionally flags normal requests as suspicious, requiring manual override or additional verification steps.
Still, that’s probably the right tradeoff. Better to err on the side of paranoia than deal with a data breach because your AI got socially engineered.
The bigger picture on AI security
This isn’t just about ChatGPT anymore. As AI agents become more capable of taking real-world actions, the stakes for security failures keep climbing. OpenAI’s defense system represents a necessary evolution in how these models handle potentially risky requests.
Yet the fundamental challenge remains: AI systems that can be fooled by clever language will always be vulnerable to cleverer language. The question isn’t whether these defenses are perfect, but whether they’re good enough to make attacks significantly harder and less reliable.
Based on OpenAI’s implementation, the answer seems to be yes, for now. The company has created meaningful barriers that should deter casual attackers and make professional ones work considerably harder. That’s progress, even if it’s not a permanent solution to the prompt injection problem.
https://openai.com/index/designing-agents-to-resist-prompt-injection



